
Compartir:
Benjamin Aronov es desarrollador de Vonage. Es un constructor de comunidades con experiencia en Ruby on Rails. Benjamin disfruta de las playas de Tel Aviv, a la que llama hogar. Su base en Tel Aviv le permite conocer y aprender de algunos de los mejores fundadores de startups del mundo. Fuera de la tecnología, a Benjamin le encanta viajar por el mundo en busca del perfecto pain au chocolat.
Cómo construir una jerarquía de clasificación de intenciones
Tiempo de lectura: 10 minutos
Los agentes conversacionales de IA son una excelente forma de ahorrar a su empresa su recurso más importante: ¡el tiempo de los empleados! Los agentes son como las preguntas frecuentes interactivas, pero mucho más flexibles. Si se crean correctamente, pueden ayudar a mejorar drásticamente la experiencia del cliente. Pero la pregunta es, ¿cómo crearlos correctamente?
Afortunadamente, el equipo de AI Studio ha hecho el trabajo duro por ti. Hemos conseguido mejorar considerablemente el rendimiento de los agentes de IA de gran tamaño (más de 50 intentos). Gracias a estas técnicas, algunos agentes han aumentado en un 55% el número de llamadas realizadas con éxito y han reducido en un 83% las solicitudes a agentes humanos.
En este artículo se explica cómo crear una jerarquía en Clasificación de intenciones para mejorar el rendimiento de los agentes a la hora de dirigir a los usuarios a la intención correcta. Los temas incluirán las mejores prácticas generales de NLU, ejemplos de construcción de una clasificación jerárquica y consejos sobre el diseño de su agente de IA conversacional en AI Studio.
¿Qué es NLU? Comprensión del Lenguaje Naturalo NLU, es el proceso que permite a un ordenador comprender la intención de un texto. NLU es la forma en que un ordenador entiende lo que un usuario quiere decir cuando habla con él. El software lo hace mediante la Clasificación de Intenciones y la Extracción de Entidades.
La Clasificación de Intenciones parece bastante sencilla, ¿verdad? El Agente simplemente descompone la entrada del usuario y la asigna a sus intenciones definidas. Pero en la práctica, es muy fácil confundir el modelo.
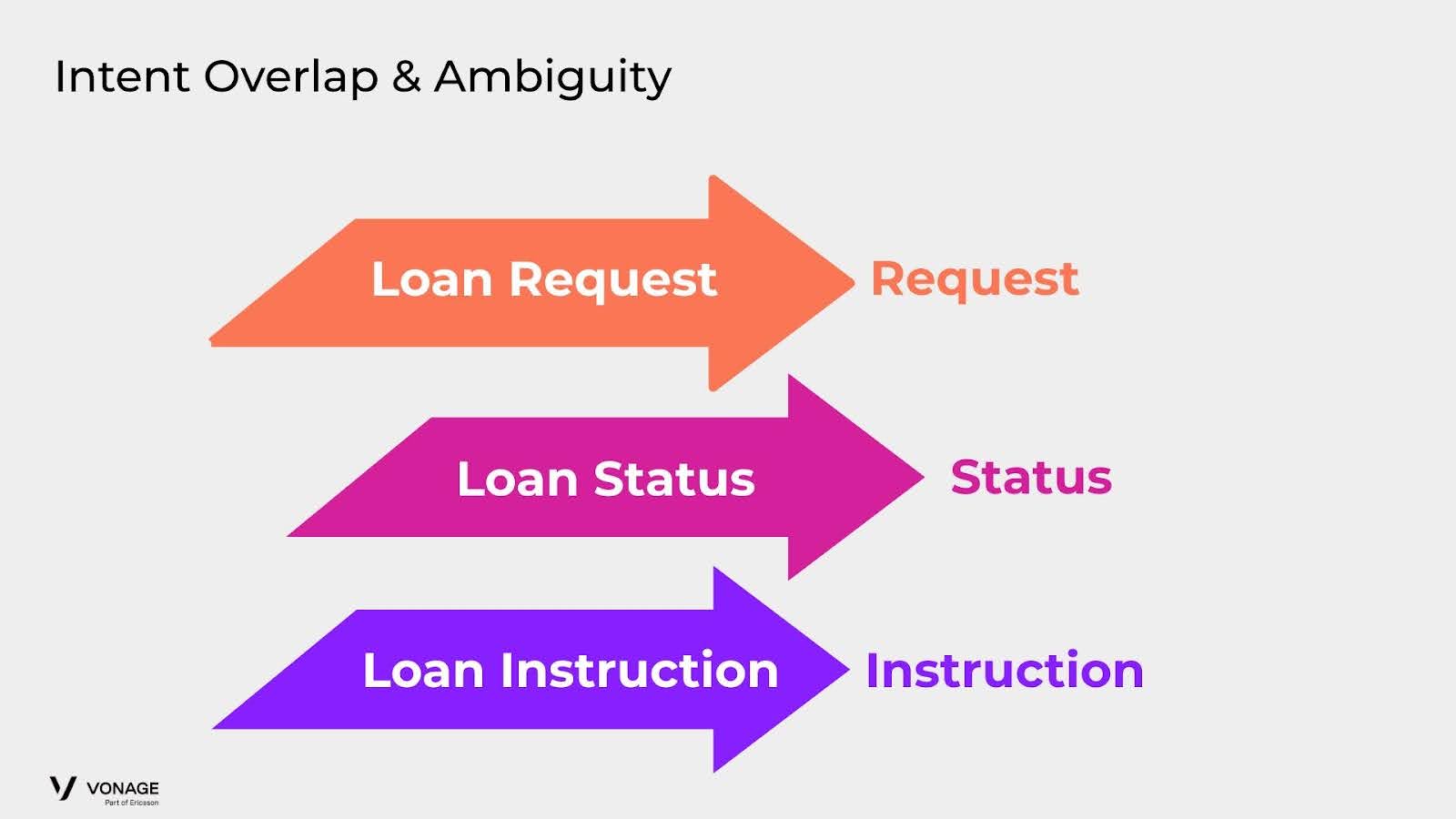
Consideremos el escenario de un agente diseñado para una institución financiera como un banco. En este contexto, los clientes pueden iniciar varias interacciones relacionadas con los préstamos, como realizar una solicitud de préstamo, comprobar el estado del préstamo o buscar información general sobre el préstamo.
El reto surge cuando términos como "préstamo" o "hipoteca" se emplean en diversos contextos, como en frases como "hablar con un representante hipotecario" u "obtener una oferta hipotecaria". Este uso generalizado de las mismas palabras clave dentro de un mismo nodo de clasificación puede dar lugar a una clasificación errónea por parte del modelo.
Para mitigar este problema, proponemos implementar una estructura jerárquica con dos capas, compuesta esencialmente por dos nodos de clasificación. La primera capa se centraría en clasificar el concepto central, como "préstamo" o "hipoteca", mientras que la segunda se especializaría en discernir la acción o intención específica asociada a la consulta del usuario (solicitud, estado, representante, etc.). Este enfoque jerárquico pretende aumentar la precisión del modelo y reducir la probabilidad de clasificar erróneamente intenciones similares pero contextualmente distintas.
 Intent Overlap & Ambiguity
Intent Overlap & Ambiguity
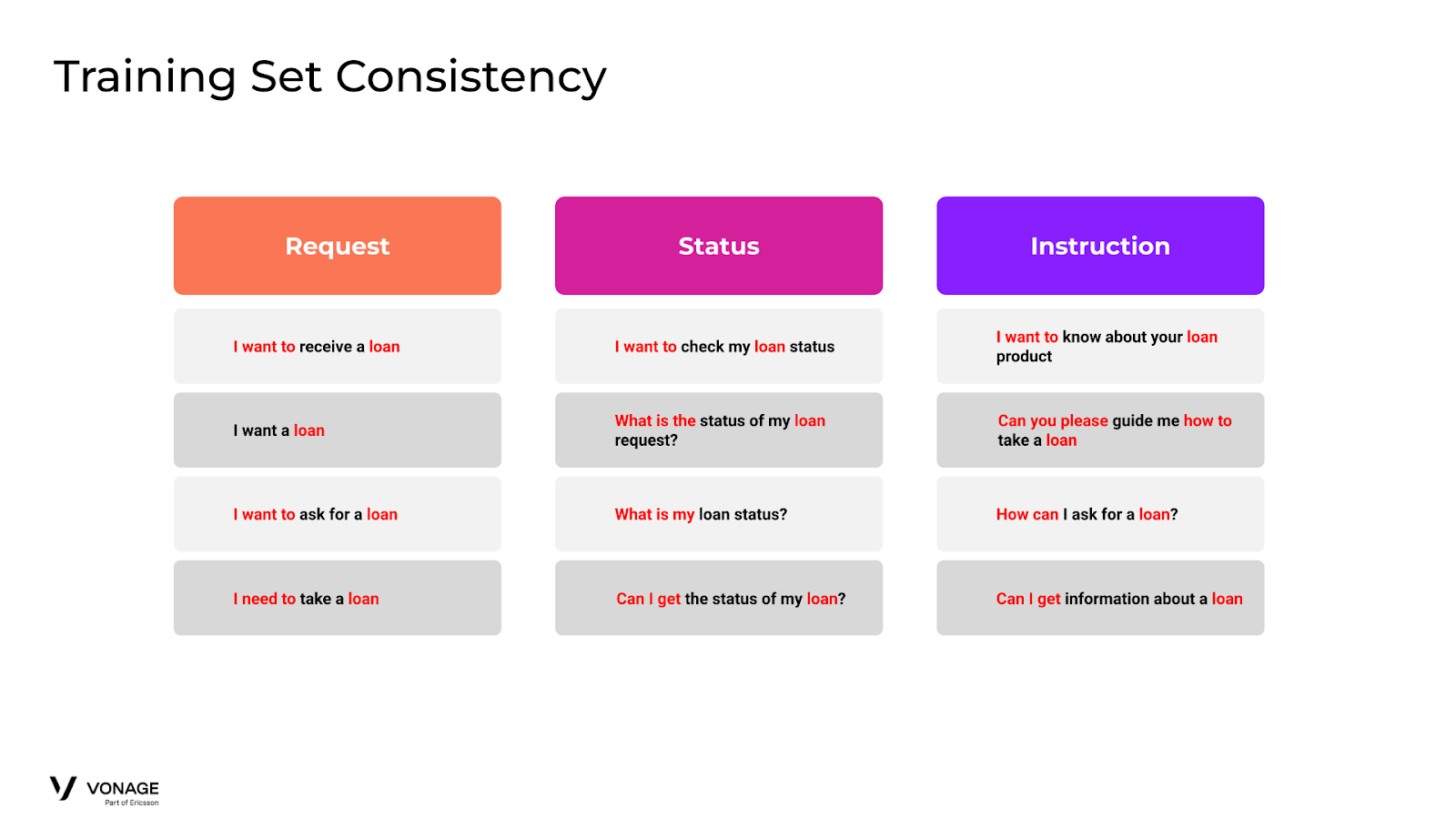
Además, dado que los conjuntos de entrenamiento que componen cada intent tendrán expresiones muy similares, debemos ser extremadamente coherentes. Añadir palabras ambiguas en los conjuntos de entrenamiento puede provocar un comportamiento inesperado si se aplica de forma incoherente.
Por ejemplo, imagine que su intención de solicitud de préstamo contiene la expresión "Quiero pedir un préstamo". Ahora un usuario le pregunta a su agente, "Quiero preguntar por el estado de un préstamo", que debería dirigirlo a (Préstamo) Estado. A menos que su conjunto de datos de entrenamiento para Estado incluya una expresión con la frase "quiero" y "préstamo", hay una probabilidad muy alta de que se dirija incorrectamente a Solicitud. Para resolver este problema, sus datos de entrenamiento deben ser extremadamente consistentes con las palabras ambiguas de relleno/apoyo. Así que, o bien las añade en todas partes, o bien las elimina en todas partes. A menudo es más fácil omitirlas.
 Training Set Consistency
Training Set Consistency
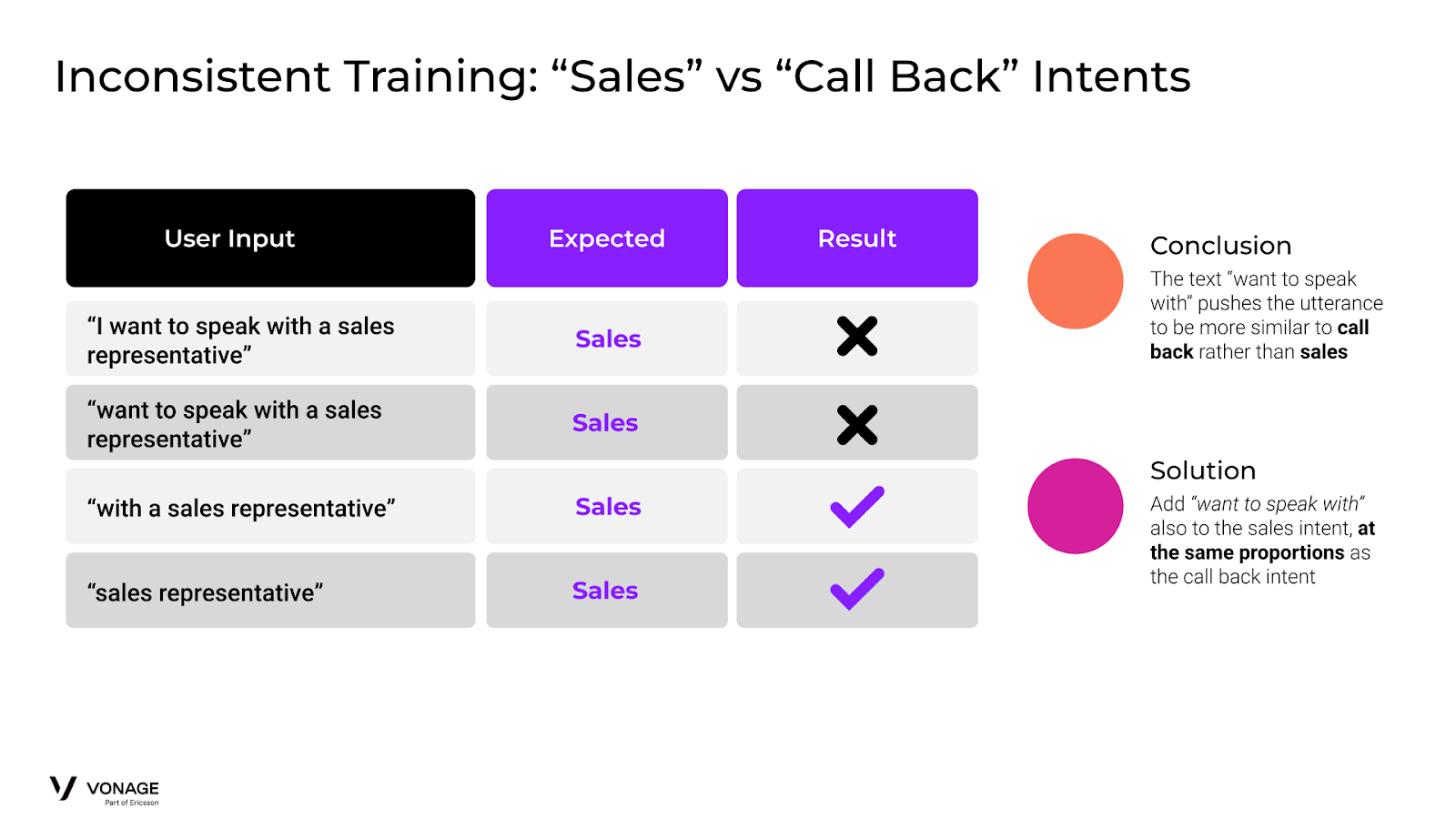
Ahora imaginemos que queremos añadir dos nuevos intentos a nuestro agente bancario: Devolución de llamada y Ventas. Call Back es para los usuarios que quieren que un representante de atención al cliente les devuelva la llamada y Sales es para que alguien del departamento de Ventas les llame.
 Inconsistent Training Example
Inconsistent Training Example
Esperamos que todo lo siguiente se clasifique como "ventas":
Quiero hablar con un comercial
desea hablar con un comercial
con un comercial
representante comercial
Sin embargo, como vemos en el diagrama, las dos primeras entradas de usuario que tienen "desea hablar con" acaban clasificándose como "devolución de llamada". Esto se debe a que las palabras "hablar con" son más parecidas a devolución de llamada que a ventas.
La solución es añadir datos de entrenamiento a nuestra intent "ventas" que contengan "desea hablar con". Debe tener la misma proporción que los datos de entrenamiento para datos de entrenamiento similares en el conjunto de entrenamiento de "devolución de llamada".
En un agente más complicado, estas dos intenciones pueden parecer muy similares en comparación con otras intenciones. En breve veremos cómo la clasificación jerárquica ayudará a nuestro agente a llegar al punto en el que pueda hacer esta distinción más granular.
Sanear nuestros Intents para evitar el solapamiento de Intents y asegurar que nuestros Conjuntos de Entrenamiento son consistentes son un buen comienzo para mejorar la Clasificación, pero una vez que empezamos a tener agentes con muchos intents, no será suficiente ya que el mundo está lleno de inevitables solapamientos. Y esos molestos usuarios nunca se comportan como queremos.
La clasificación jerárquica ayuda con estos agentes a gran escala, ya que crea niveles de clasificación para centrar la clasificación sólo en una variable o tema a la vez. Al clasificar por etapas, el agente es más eficaz al categorizar las intenciones en grupos según sus mayores diferenciadores. Agrupar por su mayor diferenciación ayuda a eliminar el solapamiento y la ambigüedad.
Desglosar nuestra clasificación en etapas puede parecer sencillo, pero enseguida vemos que hay distintas formas de agrupar las intenciones. Podemos agruparlas por sus nombres o por sus verbos.
Los sustantivos son los elementos de su agente sobre los que un usuario puede preguntar. Piense en ellos como los objetos directos de su solicitud. Suelen ser los productos o servicios que ofrece su empresa. Ejemplos de sustantivos serían "salida tardía", "paquete de cumpleaños" y "consulta 1:1".
Los verbos, por su parte, son la acción que alguien quiere realizar sobre el sustantivo. Considere las diferencias entre las peticiones de los clientes de "RESERVAR una reserva", "CANCELAR una reserva" y "CAMBIAR una reserva".
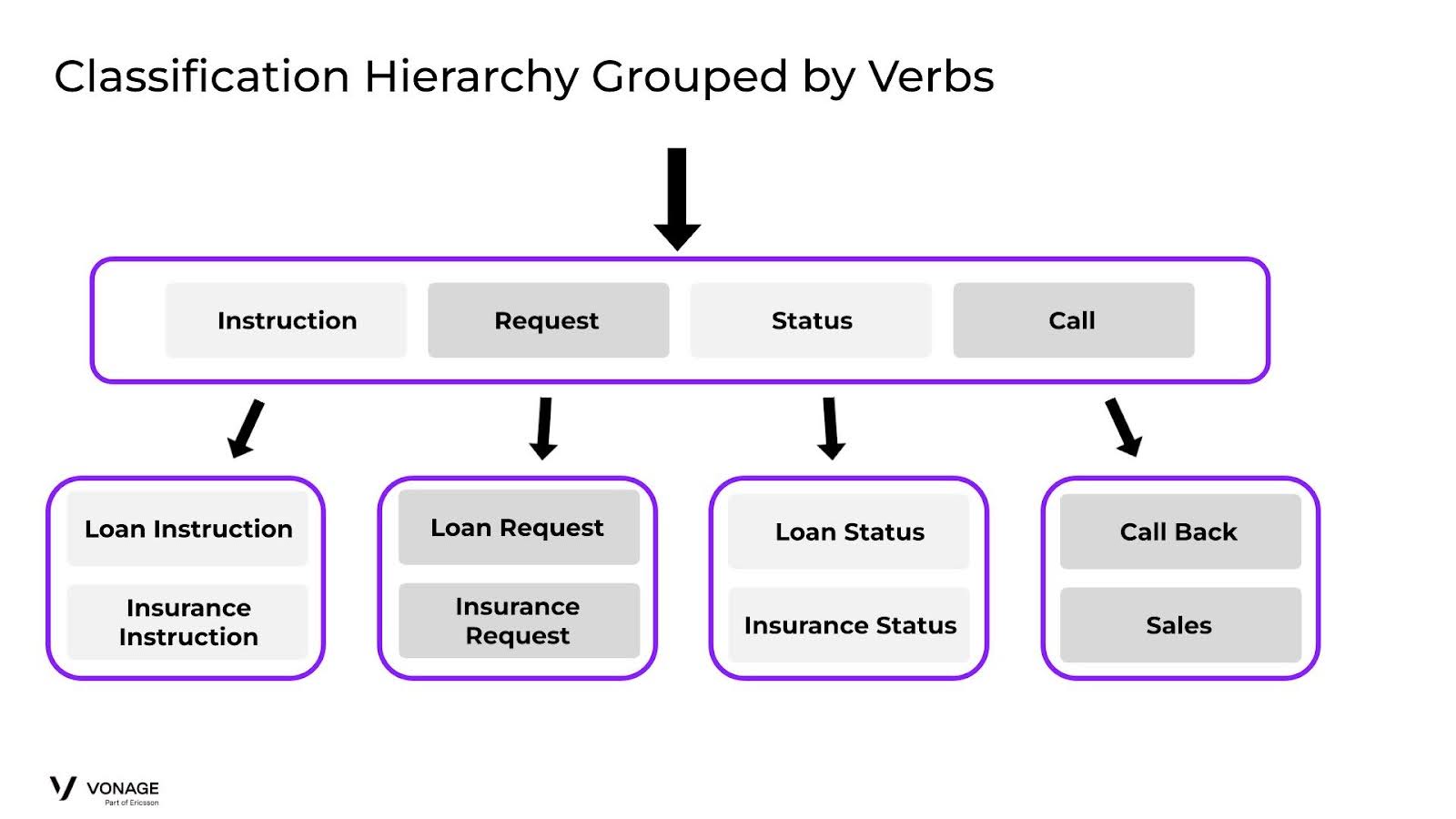
Imaginemos que ampliamos nuestro escenario bancario. En lugar de ofrecer sólo préstamos, también queremos empezar a ofrecer seguros. En el caso de los seguros, también damos al usuario la opción de solicitar un seguro, comprobar el estado del seguro e información general sobre el seguro. Ahora, nuestro clasificador tiene que comparar los datos introducidos por el usuario con una gran cantidad de datos de entrenamiento, que intrínsecamente empezarán a solaparse.
Este es exactamente el escenario en el que la jerarquía mejorará el rendimiento de nuestro agente. El primer paso es agrupar nuestros temas. En este ejemplo, tenemos varias formas de agrupar los temas. Podemos agruparlos por productos o por servicios.
Este diagrama ilustra cómo podríamos agrupar por verbos:
 Hierarchy Grouped By Verbs
Hierarchy Grouped By Verbs
Aunque los grupos tienen un sentido lógico y podríamos pasar el clasificador inicial con resultados elevados, ¿qué ocurrirá en la segunda fase de clasificación? Como hemos visto antes, el clasificador tendrá problemas en la segunda ronda, ya que es probable que haya una gran ambigüedad al comparar entradas de usuario que parezcan Instrucción de Préstamo e Instrucción de Seguro. En estos casos, habrá un alto solapamiento en los Conjuntos de Entrenamiento y tendremos que ser muy meticulosos para mantener la coherencia de los datos.
Ahora, intentemos ver qué ocurre cuando agrupamos las Intents por sustantivos:
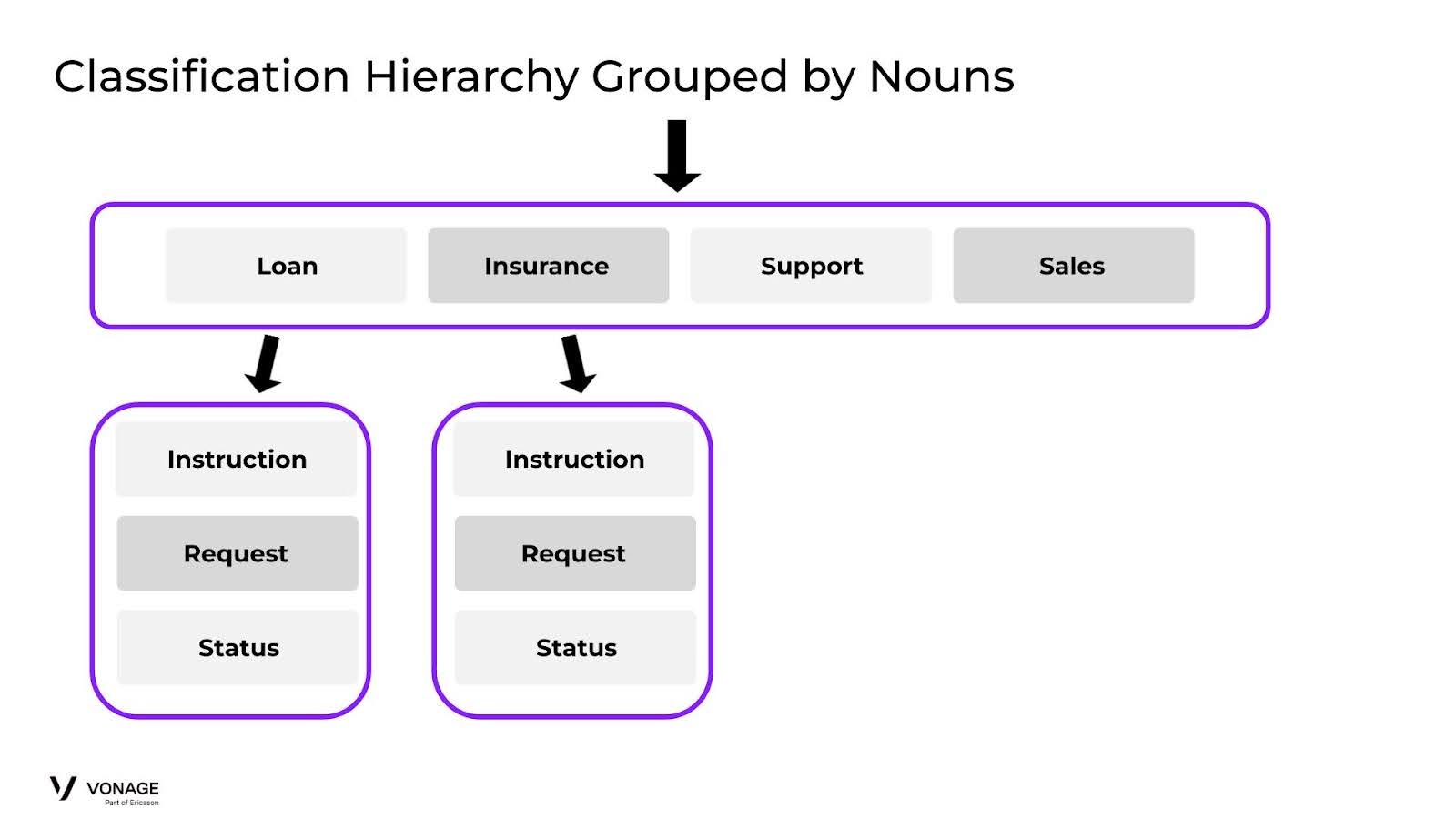 Hierarchy Grouped By Nouns
Hierarchy Grouped By Nouns
Lo que vemos aquí es que no sólo eliminamos una capa de complejidad al diferenciar inmediatamente entre Asistencia y Ventas, sino que, lo que es más importante, creamos agrupaciones en la 2ª ronda que son mucho más fáciles de clasificar. En cada grupo de Préstamos y Seguros, cada Intención puede desglosarse para tener muy poco solapamiento como hicimos antes.
Ahora que ya entiendes la teoría, vamos con una guía práctica.
Si tienes datos del mundo real, ¡es fantástico! Salta al paso número 2, puedes centrarte en los datos de entrenamiento principales y dejar de lado los valores atípicos por ahora.
Si no, imagina que tus usuarios hablan sin utilizar palabras de relleno ni palabras adicionales innecesarias. Ahora escriba todas las expresiones de usuario que se le ocurran. Este es su conjunto de entrenamiento idealizado.
Imagine todos los sinónimos posibles para sus productos/ofertas.
Ejemplo: habitación/reserva/reserva/estancia
Al igual que organizamos los temas del Banco en grandes grupos en torno a sustantivos, usted también debe agrupar sus temas en grandes categorías de sustantivos/frase nominal. A partir de ahí, puedes empezar a identificar los verbos/verbos de apoyo.
En el mundo real, los usuarios se comportan como cavernícolas. Muy a menudo responden con palabras sueltas, mucho más a menudo sustantivos que verbos. Si se agrupan en torno a sustantivos, el rendimiento será mucho mayor.
¿Dónde existe un mayor potencial de ambigüedad? Para los casos muy ambiguos, añada datos de entrenamiento para normalizar y crear frases uniformes en los distintos grupos. Al igual que en el ejemplo anterior, normalice los datos de entrenamiento para los grupos con un alto grado de ambigüedad.
Después de haber resuelto la mayoría de los casos de uso, es posible que todavía tenga algunas intenciones que no encajan en sus temas de amplio alcance. ¿Dónde debe tenerlos en cuenta?
Debe añadir estas intenciones en el punto en el que tengan la mayor capacidad de ser negadas por su modelo. Considere que tiene un agente para un Nutricionista y una de sus intents es Alimentos Saludables. Sin embargo, un usuario pregunta: "¿Puedo pedir una pizza?". Lo más probable es que el modelo empuje al usuario a la intent "Alimentos saludables", aunque una pizza no debería ir ahí. Véase el diagrama:
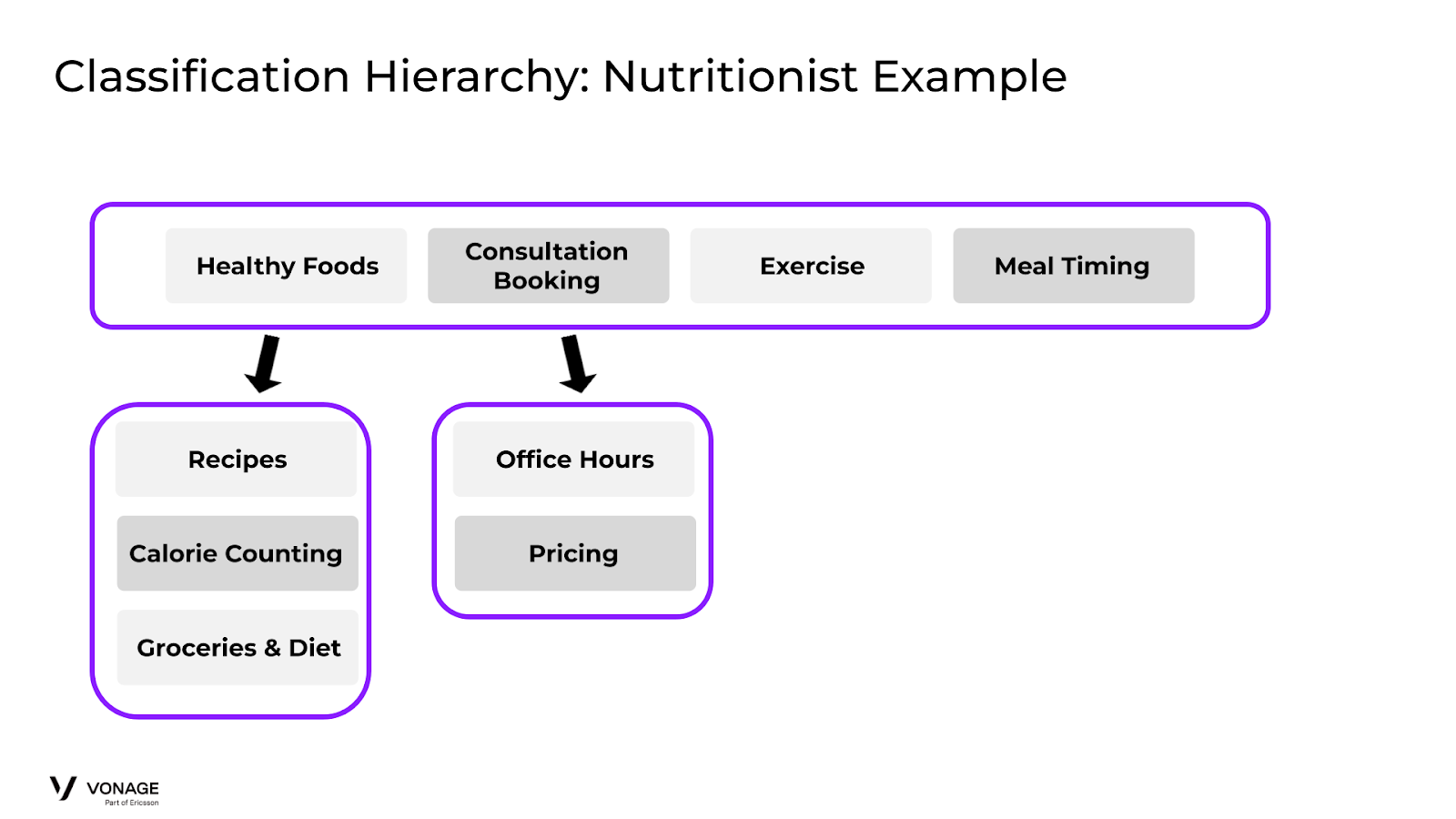 Classification Hierarchy: Nutritionist Example
Classification Hierarchy: Nutritionist Example
Nuestra solución es crear una nueva intent "negativa" para capturar el comportamiento por defecto y dirigirlo en consecuencia. Así que creamos una intent "Alimentos poco saludables" que capturará estos casos "negativos" y los dirigirá al flujo correcto. Nuestra clasificación actualizada:
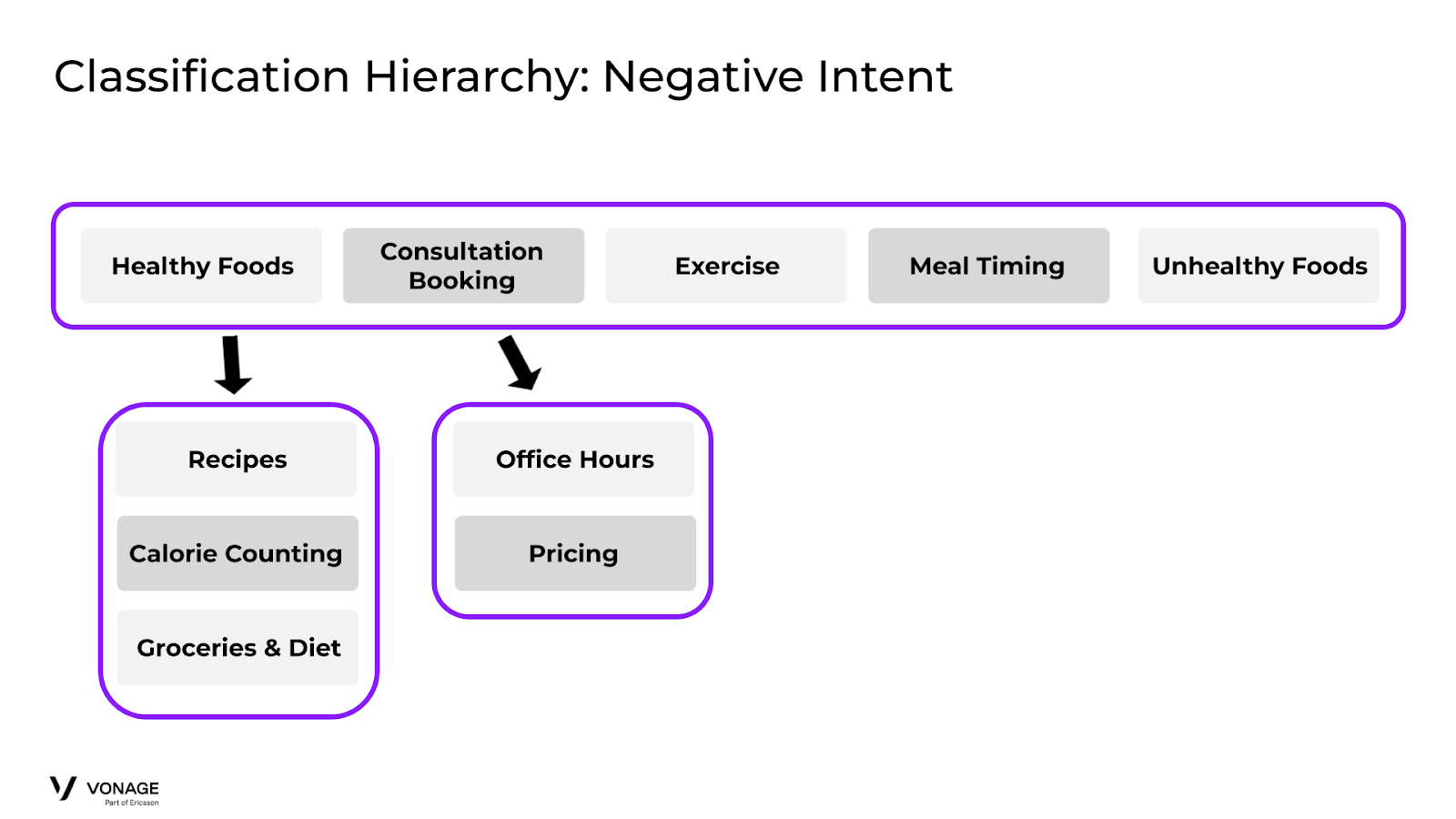 Classification Negative Intent Example
Classification Negative Intent Example
AI Studio hace que sea fácil empezar rápidamente y empezar a construir agentes con nodos de arrastrar y soltar. Sin embargo, a medida que tu agente empieza a escalar, se hace muy difícil hacer un seguimiento de docenas o cientos de nodos. No sólo la organización del agente se volverá inmanejable, sino que Studio empezará a volverse lento en la ventana del navegador, cargando un gran número de nodos.
Lo mejor es anticiparse a estos problemas planificando el agente con antelación y utilizando la función Subflujo. Para las mejores prácticas, cada intento debería tener su propio subflujo. Cada uno de estos subflujos se unirá a un Nivel de Grupo Temático. Cada uno de estos Grupos fluirá entonces hasta un nivel principal. La creación de una Clasificación Jerárquica antes de empezar a trabajar hace que la organización de sus subflujos sea una brisa y ayuda a prevenir la creación de deuda técnica futura.
Después de haber creado la primera versión de su agente, es posible que descubra que su jerarquía tiene "fugas". Un pequeño número de usuarios puede acabar accidentalmente en el flujo equivocado. En lugar de romperte la cabeza para rediseñar el modelo de jerarquía perfecto, simplemente "¡Sigue la corriente!".
Por ejemplo, consideremos este ejemplo en el que un hotel tenía un paquete de restaurante premium llamado "Nido de Águilas". Los usuarios preguntarán por "oferta premium para el Hotel" o utilizarán otra terminología porque no saben que se llama "Nido de Águilas". Había un clasificador de nivel superior para el Hotel y otro para "Nido de Águilas". Había tantos datos de entrenamiento para Hotel, que las consultas de los usuarios a menudo acababan en Hotel en lugar de en Nido de Águilas. Así que, en lugar de rediseñar todo el agente, podemos añadir un subflujo en Hotel, que luego vuelve a Eagles Nest. En el agente final, este subflujo puede vivir en 3 o 4 lugares diferentes, porque todo depende de cómo alguien puede pedirlo.
Además de que los usuarios dan entradas demasiado simplistas, a menudo dirán el tema sobre el que tienen una pregunta en lugar de una pregunta detallada. Una gran manera de manejar esto y mejorar la experiencia del usuario es crear una intención de "captura" en su nivel más alto de clasificación.
Por ejemplo, en lugar de decir: "Quiero hacer una reserva con el Dr. Smith para una operación", dirán: "Pregunta sobre la reserva" o "Pregunta sobre la operación".
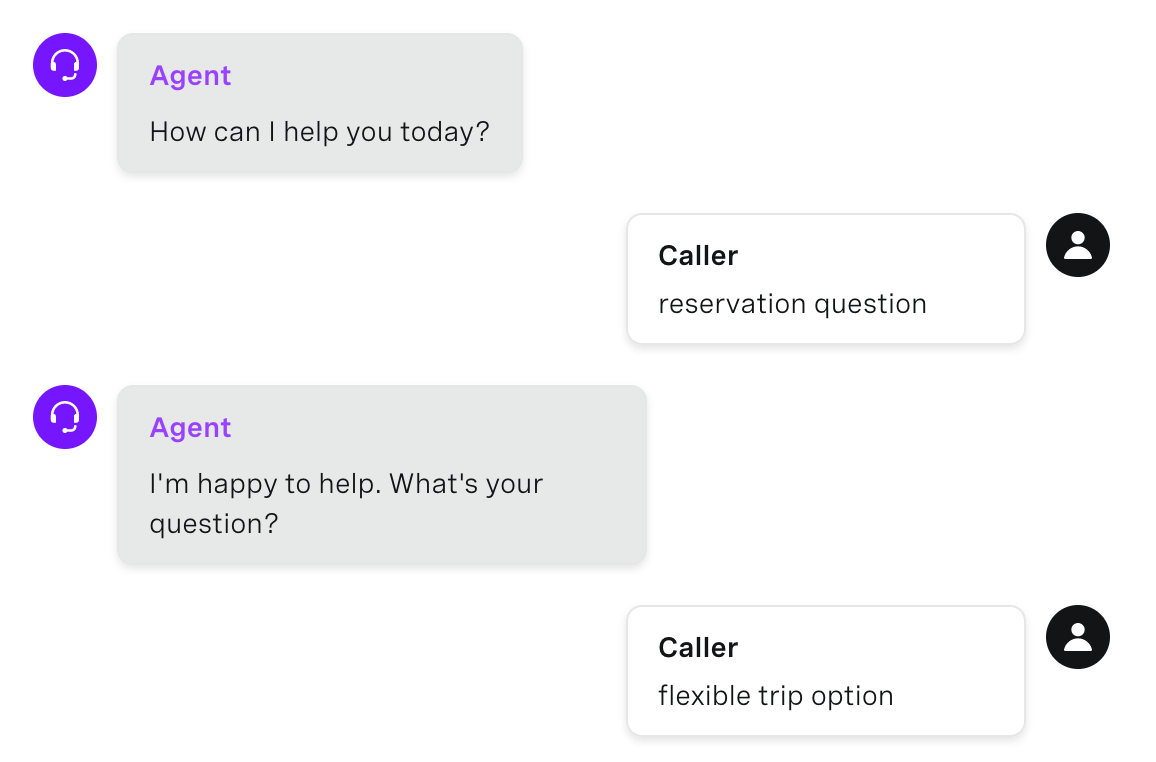 Question Deflection Example
Question Deflection Example
Descubrimos que añadir este sencillo cajón de sastre para las entradas sobre preguntas ayudaba a crear confianza en los usuarios de que el agente virtual sería capaz de ayudarles.
Ahora que has visto el poder de la Jerarquía de Clasificación en los agentes de IA Conversacional, ¡puedes ir y hacer que tus agentes sean mucho mejores respondiendo a tus usuarios! Recuerda estos pasos y serás el héroe en tu empresa:
Revisar los datos de entrenamiento
Organizar los datos, identificar dónde hay posibilidades de gran ambigüedad
Crear una clasificación jerárquica
Construir agente
Prueba, prueba, prueba
Si te ha gustado este artículo, háznoslo saber en Vonage Developer Comunidad Slack. Esta publicación se inspiró en una pregunta de un miembro de la comunidad. También puedes seguirnos en X, antes conocido como Twitterpara conocer las últimas noticias sobre la API de Vonage.
Compartir:
Benjamin Aronov es desarrollador de Vonage. Es un constructor de comunidades con experiencia en Ruby on Rails. Benjamin disfruta de las playas de Tel Aviv, a la que llama hogar. Su base en Tel Aviv le permite conocer y aprender de algunos de los mejores fundadores de startups del mundo. Fuera de la tecnología, a Benjamin le encanta viajar por el mundo en busca del perfecto pain au chocolat.