
Compartir:
Hamza es ingeniero de software y vive en Chicago. Trabaja con Webrtc.ventures, una empresa líder en soluciones WebRTC. También trabaja como Full Stack Developer en Vonage ayudando con la Plataforma de Video para servir mejor a las necesidades de sus clientes. Como orgulloso introvertido, le gusta pasar su tiempo libre jugando con sus gatos.
Mejore las Video Conferencias con ChatGPT: Conozca a su asistente de IA en directo
Tiempo de lectura: 6 minutos
La tecnología, especialmente la inteligencia artificial, ha cambiado nuestra forma de hablar y trabajar en línea. A medida que el mundo se desplaza cada vez más hacia las interacciones en línea a través de seminarios web, conferencias y reuniones individuales, es innegable la necesidad de una herramienta que pueda mejorar la productividad de estas reuniones virtuales.
Imagínese esto: un asistente de inteligencia artificial a su lado durante estas citas virtuales, listo para responder a sus preguntas, tomar notas sobre los puntos de acción y destilar la información esencial en resúmenes concisos. Hoy estamos creando un asistente de este tipo, centrado principalmente en las conversaciones uno a uno. Sin embargo, las posibilidades son ilimitadas y este concepto puede aplicarse a muchas situaciones. Así que, sin más preámbulos, ¡vamos a construir "Sushi"!
Aquí encontrará una demostración en Video:
A Cuenta API de Vonage. Accede a tu panel de API de Vonage para encontrar tu clave y secreto de API.
Un Account de OpenAI y secreto de API
Nodo 16.20.1+
npm
Para instalar la aplicación en tu máquina, primero clona el repositorio.
git clone https://github.com/hamzanasir/vonage-openai-demoAhora entra en el repositorio e instala los paquetes asociados mediante:
npm installAhora necesitamos configurar nuestra clave y secreto de API de Vonage. Comencemos copiando la plantilla .env:
cp .envcopy .envAhora todo lo que necesitas hacer es reemplazar la clave y el secreto de la API en el archivo .env con tus credenciales. Puedes encontrar tu clave y secreto de API en la página del proyecto de tu cuenta de Video API de Vonage (https://tokbox.com/account). Tu archivo .env debería tener el siguiente aspecto:
# enter your TokBox API key after the '=' sign below
TOKBOX_API_KEY=your_api_key
# enter your TokBox api secret after the '=' sign below
TOKBOX_SECRET=your_project_secretTambién necesitas crear un proyecto OpenAI. Puede hacerlo en https://platform.openai.com/signup. Una vez que te hayas registrado puedes ir a la sección Claves API para Crear una nueva clave secreta.
Pega tu clave secreta en el archivo .env.
# enter your OpenAI Secret after the '=' sign below
OPENAI_SECRET=your_openai_secretUna vez hecho esto, puedes iniciar la aplicación con:
npm startAhora vaya a http://localhost:8080/. Para comenzar a conversar con Sushi, asegúrate de presionar los botones de inicio de subtítulos en la parte inferior izquierda para iniciar el servicio Live Caption de Vonage. Para una mejor experiencia, asegúrate de usar auriculares para que la voz de Sushi no se retroalimente con el micrófono del editor.
Todo el código del que hablamos en este blog se encuentra en el archivo public/js/app.js archivo. Si tienes curiosidad por saber cómo funcionan los subtítulos en directo, no dejes de consultar el archivo routes/index.js para ver cómo se inicia y se detiene el servicio de subtítulos.
Para comprender el funcionamiento interno de nuestro asistente virtual, profundicemos en su marco arquitectónico.
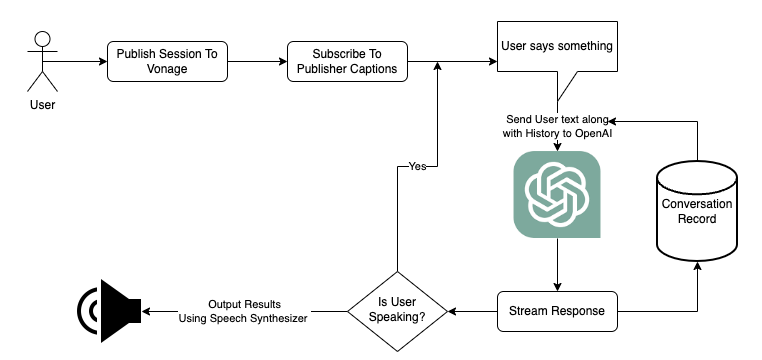
En el corazón de esta configuración se encuentra la gestión de las conversaciones e interacciones de los usuarios con la API de OpenAI. Hemos elegido el modelo GPT-3.5 Turbo de OpenAI, que destaca en la gestión de conversaciones. Sin embargo, OpenAI ofrece una variedad de modelos para adaptarse a los objetivos específicos de tu proyecto.
Cuando enviamos una solicitud a GPT, tarda un momento en elaborar una respuesta. Adoptemos un enfoque más dinámico. Transmitimos los datos a medida que se generan, lo que garantiza una experiencia de conversación más rápida y natural. Este enfoque también permite a los usuarios interrumpir y guiar la conversación, imitando las interacciones de la vida real.
A medida que GPT formula su respuesta, convertimos el texto generado en voz audible utilizando un sintetizador de voz. Hay varias opciones disponibles para este fin, incluidos sintetizadores de voz de pago de terceros que pueden ofrecer una voz con un sonido más natural. Para nuestro proyecto, hemos optado por el módulo nativo SpeechSynthesisUtterance del navegador. Para gestionar las interrupciones de la voz del usuario, utilizaremos el AbortController del navegador.
Veamos cómo iniciamos y gestionamos nuestro servicio de subtitulado, un componente fundamental de nuestro sistema.
Para empezar, activamos el servicio de subtitulado llamando a nuestro servidor mediante POST a /captions/start, proporcionándole nuestro identificador de sesión. Con esta configuración, estamos listos para recibir subtítulos para todos los suscriptores de la sesión. Sin embargo, también queremos que se generen nuestros propios subtítulos como editor. Para conseguirlo, nos suscribimos a nuestro propio editor con volumen cero, asegurándonos de que no se repite nuestra propia voz.
Aquí tienes un fragmento del código que lo hace posible:
const publisherOptions = {
insertMode: 'append',
width: '100%',
height: '100%',
publishCaptions: true,
};
publisher = OT.initPublisher('publisher', publisherOptions, (err) => {
if (err) {
handleError(err);
} else {
session.publish(publisher, () => {
if (error) {
console.error(error);
} else {
const captionOnlySub = session.subscribe(
publisher.stream,
document.createElement('div'),
{
audioVolume: 0
},
);
speakText(greetingMessage);
captionOnlySub.on('captionReceived', async (event) => {
if (event.isFinal) {
stopAiGenerator();
startAiGenerator(event.caption)
}
});
}
});
}
});
En este código, publicamos nuestro audio y video en la sesión y luego nos suscribimos a la misma instancia para recibir nuestros subtítulos. Para que este proceso funcione a la perfección, adjuntamos un manejador de eventos 'captionReceived' a nuestro suscriptor simulado. Este manejador de eventos captura la transcripción de nuestro discurso a medida que hablamos. Dado que este evento suele dispararse periódicamente a medida que hablamos, utilizamos el booleano 'isFinal' para identificar cuándo hemos terminado de hablar. Una vez que nuestro texto generado está listo, lo pasamos a nuestro startAiGenerator para su posterior procesamiento.
La columna vertebral de nuestra lógica se encuentra dentro de la función startAiGenerator. Dado que es una función pesada, vamos a dividirla en partes manejables. En primer lugar, vamos a echar un vistazo más de cerca a la lógica para hacer llamadas a la API:
async function startAiGenerator(message) {
let aiText = '';
let utterableText = ''
abortController = new AbortController();
const userMessage = {
'role': 'user',
'content': message
}
const reqBody = {
messages: [...messages, userMessage],
temperature: 1,
max_tokens: 256,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
model: 'gpt-3.5-turbo',
stream: true
};
try {
const response = await fetch('https://api.openai.com/v1/chat/completions', {
headers: {
'Authorization': `Bearer ${openAISecret}`,
'Content-Type': 'application/json',
},
body: JSON.stringify(reqBody),
method: 'POST',
signal: abortController.signal
});En este fragmento, tenemos dos variables, aiText y utterableText. aiText almacena la respuesta completa a nuestra consulta, mientras que utterableText captura la última frase u oración completa del flujo de datos legibles recibidos de OpenAI. También creamos una instancia de AbortController para gestionar las interrupciones del usuario mientras el asistente está hablando. Antes de iniciar el generador de IA, se llama a una función independiente, stopAiGenerator(), para detener cualquier proceso de generación de IA en curso.
function stopAiGenerator() {
if (abortController) {
abortController.abort();
abortController = null;
}
window.speechSynthesis.cancel();
}Por último, llamamos a OpenAI con el historial de las conversaciones almacenadas en el array global de mensajes. Ahora echemos un vistazo a cómo transmitimos datos desde OpenAI:
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
while (true) {
const chunk = await reader.read();
const { done, value } = chunk;
if (done) {
break;
}
const decodedChunk = decoder.decode(value);
const lines = decodedChunk.split('\n');
const parsedLines = lines
.map(l => l.replace(/^data: /, '').trim())
.filter(l => l !== '' && l !== '[DONE]')
.map(l => JSON.parse(l));
for (const line of parsedLines) {
const textChunk = line?.choices[0]?.delta?.content;
if (textChunk) {
utterableText += textChunk
if (textChunk.match(/[.!?:,]$/)) {
speakText(utterableText);
utterableText = '';
}
aiText += textChunk;
}
}
}
En este segmento, iniciamos el lector desde el objeto fetch que utilizamos para solicitar GPT. Empleamos un bucle while para leer continuamente del flujo hasta que se agote. Para cada trozo de texto, lo añadimos a las dos variables definidas anteriormente. Si un trozo incluye un signo de puntuación, activamos la función speakText(), que vocaliza la última oración o frase generada y restablece utterableText a una cadena vacía. Recuerda que este proceso puede detenerse en cualquier momento mediante una señal de parada de nuestro AbortController.
Por último, tanto si terminamos el flujo como si permitimos que se complete, guardamos tanto la entrada del usuario como la respuesta de OpenAI de la siguiente manera:
messages.push(userMessage);
messages.push({
content: aiText,
role: 'assistant'
})
La "ingeniería de instrucciones" en el procesamiento del lenguaje natural implica elaborar instrucciones o preguntas para guiar a los modelos de IA. Se trata de encontrar el equilibrio adecuado entre claridad y ambigüedad para lograr resultados específicos. Con la ingeniería de instrucciones adecuada, puedes convertir a Sushi en un falso asesor jurídico, un experto médico, un amigo descarado, etc. Para esta demostración, vamos a utilizar esta pregunta:
const messages = [
{
'role': 'system',
'content': "You are a participant called Sushi in a live call with someone. Speak concisely, as if you're having a one-on-one conversation with someone. " // Prompt engineering for AI assistant
}
];Pruebe a cambiar el contenido de este código para ver cómo se comporta el asistente.
Esta sección del proyecto tiene margen para la flexibilidad. Puedes optar por soluciones más naturales y avanzadas para la síntesis de voz. La mayoría de ellas serán de pago, por lo que en esta demo optaremos por la funcionalidad SpeechSynthesisUtterance por defecto del navegador.
function speakText(text) {
let captions = '';
const utterThis = new SpeechSynthesisUtterance(text);
utterThis.voice = voices.find((v) => v.name.includes('Samantha'));
utterThis.onboundary = (event) => {
captions += `${event.utterance.text.substring(event.charIndex, event.charIndex + event.charLength)} `;
displayCaptions(captions, 'ai-assistant');
};
utterThis.onstart = () => {
animateVoiceSynthesis();
};
utterThis.onend = function() {
stopAnimateVoiceSynthesis();
};
window.speechSynthesis.speak(utterThis);
}
Así que primero, inicializamos el módulo SpeechSynthesisUtterance con el texto que queremos pronunciar. Después de eso, necesitamos establecer una Voice disponible en el navegador. Estos se cargan de forma asíncrona así:
let voices = window.speechSynthesis.getVoices();
if (speechSynthesis.onvoiceschanged !== undefined)
speechSynthesis.onvoiceschanged = updateVoices;
function updateVoices() {
voices = window.speechSynthesis.getVoices();
}Utilizamos la función onstart y onend para animar las barras del centro e ilustrar cuándo está hablando Sushi. Además, el evento onboundary se utiliza para insertar subtítulos de texto para mostrar qué palabra está diciendo el sintetizador de voz.
Es importante tener en cuenta que esto es sólo un ejemplo de lo que se puede hacer con una integración con GPT. El propósito de esta demostración es mostrar cómo puedes crear la canalización entre Vonage Video Live Captions y OpenAI, pero el cielo es el límite de lo que puedes construir con indicaciones elaboradas por expertos.
Consulte la sección de sección de ejemplos de GPT para ver la infinidad de aplicaciones. ¡Estamos deseando ver lo que vas a crear!
Cuéntanos qué estás creando con Vonage Video API. Chatea con nosotros en nuestra Comunidad de Vonage Slack o X, antes conocido como Twitter, @VonageDev.
Compartir:
Hamza es ingeniero de software y vive en Chicago. Trabaja con Webrtc.ventures, una empresa líder en soluciones WebRTC. También trabaja como Full Stack Developer en Vonage ayudando con la Plataforma de Video para servir mejor a las necesidades de sus clientes. Como orgulloso introvertido, le gusta pasar su tiempo libre jugando con sus gatos.