
Compartir:
Steve es un antiguo miembro del equipo de Vonage. Fue promotor de desarrolladores .NET en Vonage, ingeniero de software poliglota y full-stack, especializado en IA y aprendizaje automático.
Creación de un servicio de transcripción .NET en tiempo real
Tiempo de lectura: 5 minutos
Crear servicios de transcripción de voz a texto nunca ha sido tan fácil. En esta demostración se creará un servicio de transcripción en tiempo real extremadamente sencillo, pero potente, en ASP.NET utilizando el SDK .NET de Vonage y SDK de voz de Microsoft Azure.
Visual Studio 2019 versión 16.3 o superior
Una Account Azure
Opcional: Ngrok para el despliegue de prueba
Vaya a su Azure Dashboard
Abra el menú Hamburguesa y seleccione "Crear recurso".
Buscar discurso y crear un recurso de discurso:
Rellene el formulario de creación. A título demostrativo, puede utilizar las siguientes entradas
Nombre: TranscriptionTest
Suscripción: pago por uso
Localización: Este de EE.UU.
Nivel de precios: F0
Grupo de recursos: Transcripción
Esto tomará algún tiempo para girar para arriba. Una vez desplegado, ve a la sección de inicio rápido para reunir tus claves de acceso. Usted está buscando el Key1 así que busca la sección resaltada:
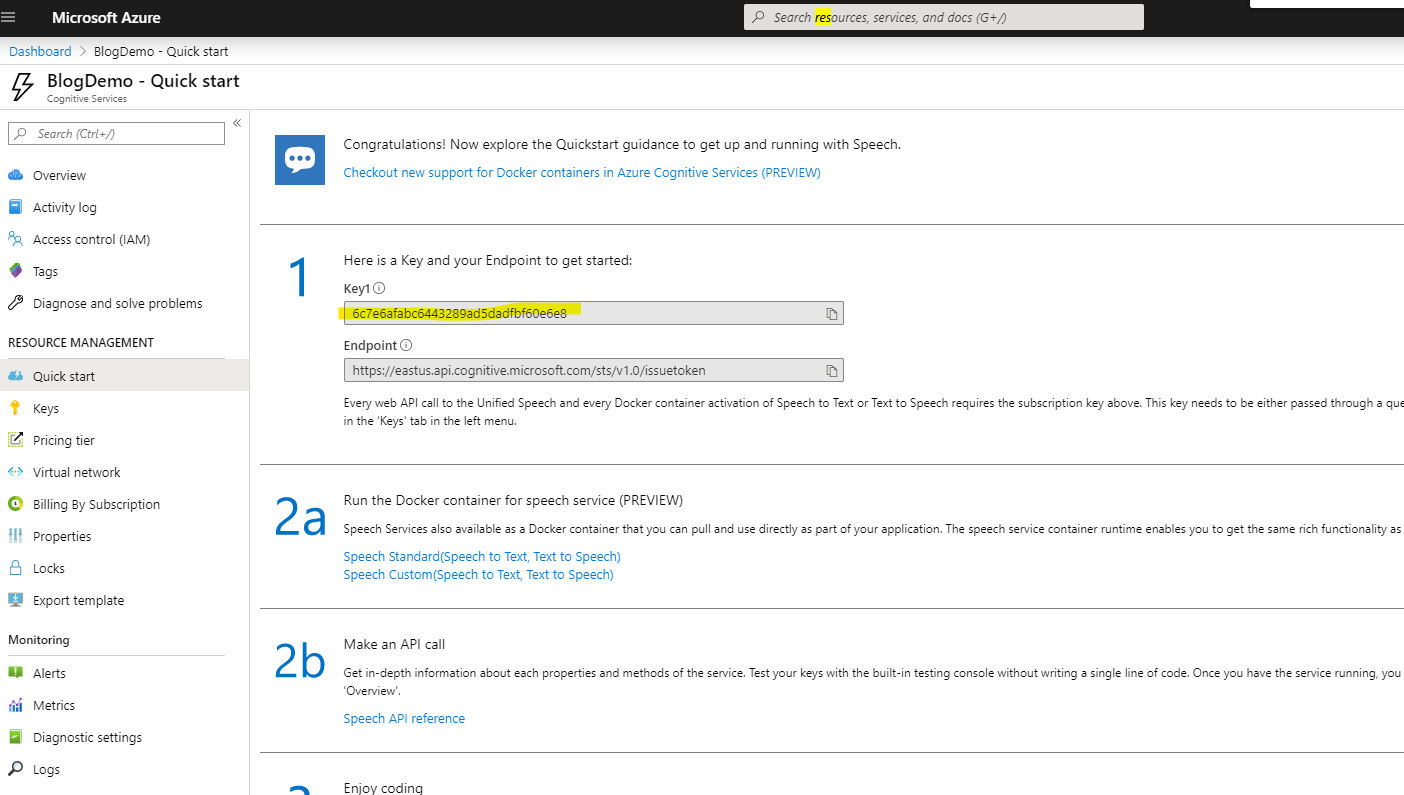
Guarde este valor clave fuera de línea en algún lugar por el momento.
Abra Visual Studio y cree un nuevo proyecto ASP.NET Core WebApplication. Por ejemplo, "TranscriptionBlogPostDemo".
Ahora, crearás una aplicación web MVC para esta demostración en ASP.NET Core 3.0.
Con esto creado, añade los siguientes paquetes nuget al proyecto:
Nexmo.Csharp.Cliente
Newtonsoft.Json
Microsoft.CognitiveServices.Speech
Con estos proyectos importados, crea una nueva clase llamada TranscriptionEngine.
En primer lugar, defina algunas constantes en beneficio tanto del SDK de voz como de la gestión del búfer WebSocket.
const int SAMPLES_PER_SECOND = 8000;
const int BITS_PER_SAMPLE = 16;
const int NUMBER_OF_CHANNELS = 1;
const int BUFFER_SIZE = 160 * 2;A continuación, añada el siguiente campo a la clase:
_config - contendrá la información de suscripción/región del analizador de voz. La región de la demostración es eastus, derivada de la región para la que configuró el servicio de voz. Para un mapeo de la región a la cadena de entrada ver el Microsoft Azure Speech Service Regiones Soportadas Documentación
inputStream - será un flujo push que servirá como búfer que se transmitirá al servicio Azure Speech-to-text.
_audioInput - esta será la entrada para el reconocedor de voz
_recognizer - este será el reconocedor que realizará la tarea de reconocimiento de voz
Se pueden definir así:
SpeechConfig _config = SpeechConfig.FromSubscription("your_subscription_key", "your_azure_region"); // e.g. eastus
PushAudioInputStream _inputStream = AudioInputStream.CreatePushStream(AudioStreamFormat.GetWaveFormatPCM(SAMPLES_PER_SECOND, BITS_PER_SAMPLE, NUMBER_OF_CHANNELS));
AudioConfig _audioInput;
SpeechRecognizer _recognizer;Dado que varios de los campos son IDisposable's, haga que esta clase implemente IDisposable y simplemente disponga de todos los campos desechables en su camino hacia abajo
public void Dispose()
{
_inputStream.Dispose();
_audioInput.Dispose();
_recognizer.Dispose();
}A continuación, añada un constructor que inicializará _audioInput con el flujo de entrada push definido anteriormente:
public TranscriptionEngine()
{
_audioInput = AudioConfig.FromStreamInput(_inputStream);
}A continuación, añade el método que escuchará los eventos de reconocimiento de voz del reconocedor
private void RecognizerRecognized(object sender, SpeechRecognitionEventArgs e)
{
Trace.WriteLine("Recognized: " + e.Result.Text);
}Desde aquí, puedes añadir una función para detener e iniciar el reconocedor de voz.
El método start acepta una cadena de idioma, establece el idioma de la SpeechConfig, inicializa el reconocedor con la configuración y la fuente de entrada de audio, registra el evento RecognizerRecognized que creó anteriormente e inicia un Reconocimiento continuo.
Su método stop anulará el registro del evento RecognizerRecognized y detendrá el reconocedor.
NOTA: StopContinuousRecognitionAsync puede tardar más de 20 segundos, ya que no existe un mecanismo para cancelar el flujo de entrada que se está ejecutando en ese momento. Esta demo mitiga explícitamente este problema al no reutilizar el reconocedor entre llamadas, y no bloquear el cierre del socket para que esto se complete.
public async Task StartSpeechTranscriptionEngine(string language)
{
_config.SpeechRecognitionLanguage = language;
_recognizer = new SpeechRecognizer(_config, _audioInput);
_recognizer.Recognized += RecognizerRecognized;
await _recognizer.StartContinuousRecognitionAsync();
}
private async Task StopTranscriptionEngine()
{
if(_recognizer != null)
{
_recognizer.Recognized -= RecognizerRecognized;
await _recognizer.StopContinuousRecognitionAsync();
}
}La tarea final de esta clase va a ser recibir audio en el websocket que se va a establecer, y empujarlo a través del PushAudioStream que se creó anteriormente. Esto será esperado después de que el websocket sea establecido y continuará así hasta que el websocket sea cerrado.
public async Task ReceiveAudioOnWebSocket(HttpContext context, WebSocket webSocket)
{
var buffer = new byte[BUFFER_SIZE];
try
{
var language = "en-US";
await StartSpeechTranscriptionEngine(language);
WebSocketReceiveResult result = await webSocket.ReceiveAsync(new ArraySegment<byte>(buffer), CancellationToken.None);
while (!result.CloseStatus.HasValue)
{
await webSocket.SendAsync(new ArraySegment<byte>(buffer, 0, result.Count), result.MessageType, result.EndOfMessage, CancellationToken.None);
result = await webSocket.ReceiveAsync(new ArraySegment<byte>(buffer), CancellationToken.None);
_inputStream.Write(buffer);
}
await webSocket.CloseAsync(result.CloseStatus.Value, result.CloseStatusDescription, CancellationToken.None);
}
catch (Exception e)
{
Trace.WriteLine(e.ToString());
}
finally
{
await StopTranscriptionEngine();
}
}NOTA: El búfer inicial que reciba del websocket contendrá metadatos para la llamada y, si lo desea, puede extraer estos datos del primer ReceiveAsync; por el bien de la demostración, esto no se hace, ya que el búfer y el Recognizer son lo suficientemente robustos como para gestionarlos.
Abrir Startup.cs.
En el método Configure, habilitarás websockets en el servidor y proporcionarás una pieza de websocket middleware para utilizar websockets, y para conectar un websocket entrante y utilizar el TranscriptionEngine para recibir audio a través de dicho socket.
var webSocketOptions = new WebSocketOptions()
{
KeepAliveInterval = TimeSpan.FromSeconds(120),
ReceiveBufferSize = 320
};
app.UseWebSockets(webSocketOptions);
app.Use(async (context, next) =>
{
if (context.Request.Path == "/ws")
{
if (context.WebSockets.IsWebSocketRequest)
{
WebSocket webSocket = await context.WebSockets.AcceptWebSocketAsync();
using (var engine = new TranscriptionEngine())
{
await engine.ReceiveAudioOnWebSocket(context, webSocket);
}
}
else
{
context.Response.StatusCode = 400;
}
}
else
{
await next();
}
});
La última pieza de código que necesita ser implementada es añadir un Controlador de Voice. Añade un nuevo controlador en el archivo Controller y nómbralo como VoiceController. Añade una cadena constante para el BASE_URL de tu servicio.
const string BASE_URL = "BASE_URL";Su controlador de Voice tendrá dos peticiones HTTP. Una petición POST para el webhook de eventos, y una petición GET para el webhook de respuestas. Esta solicitud GET va a construir un NCCO con una sola acción de conexión que instruirá a la Voice API para abrir un WebSocket a su servidor y empujar el flujo de audio a través de ese socket. Establezca el tipo de contenido como PCM lineal de 16 bits a 8 kHz. Véase más abajo:
[HttpPost]
public HttpStatusCode Events()
{
return HttpStatusCode.OK;
}
[HttpGet]
public string Answer()
{
var webSocketAction = new ConnectAction()
{
Endpoint = new[]
{
new WebsocketEndpoint()
{
Uri = $"wss://{BASE_URL}/ws",
ContentType="audio/l16;rate=8000",
}
}
};
var ncco = new Ncco(webSocketAction);
return ncco.ToString();
}
Abre el diálogo de propiedades de tu proyecto, en depuración toma nota del número de puerto - para la demo, desactiva SSL, lo que facilitará la configuración de ngrok.
Para que la Voice API reenvíe los webhooks de Evento/Respuesta necesita exponer el sitio a Internet - para propósitos de prueba, puede utilizar ngrok para exponer nuestro puerto IIS express. Abra su línea de comandos y utilice este comando, sustituya PORT_NUMBER por el número de puerto de su instancia de IIS Express.
ngrok http --host-header="localhost:PORT_NUMBER" http://localhost:PORT_NUMBER
Este comando produce una salida como ésta:
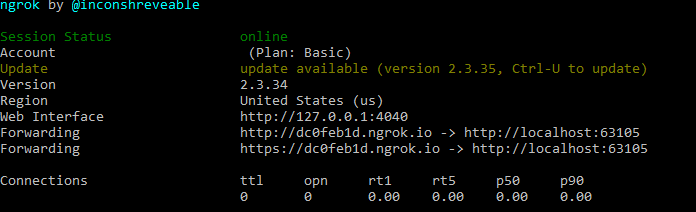
El próximo paso será configurar una aplicación de voz de Vonage.
Navega hasta tu Panel de Vonage
En el panel izquierdo, abra Voice y haga clic en "Crear una aplicación".
Asigne un nombre a la aplicación, por ejemplo "TranscriptionTest".
En Capacidades, active Voz
Para la URL de eventos, añada base_url_of_ngrok_tunnel/voice/events
Para la URL de respuesta añada base_url_of_ngrok_tunnel/voice/answer
Para la URL de respuesta Fallback añada base_url_of_ngrok_tunnel/voice/answer
Ahora que tienes la URL de ngrok, cambia la BASE_URL en el archivo VoiceController a esa url (excluyendo el 'http://')
Con esto, estarás listo y funcionando. Llama al número de Vonage vinculado a tu aplicación y la aplicación transcribirá tu voz a la consola de depuración.