
Teilen Sie:
Hamza ist ein Software-Ingenieur aus Chicago. Er arbeitet bei Webrtc.ventures, einem führenden Unternehmen, das WebRTC-Lösungen anbietet. Er arbeitet auch als Full-Stack-Entwickler bei Vonage und hilft bei der Video-Plattform, um die Bedürfnisse der Kunden besser zu erfüllen. Als stolzer Introvertierter verbringt er seine freie Zeit am liebsten mit seinen Katzen.
Voice Transkription mit Symbl.ai und der Vonage Video API
Lesedauer: 3 Minuten
Voice-Transkription, Sprache-zu-Text und Live-Untertitelung sind in der heutigen Welt, in der Video-/Audio-Meetings eine primäre Form der Kommunikation sind, sehr gefragt. Symbl.ai zeichnet sich durch Gesprächsintelligenz aus. Heute werden wir die Live-Untertitelung in unser SimplyDoc Telehealth Starter Kit mit Hilfe von Symbl.ai's Streaming und Insights API. Unser Video und Audio wird unterstützt von Video API von Vonage. Lassen Sie uns beginnen.
Wir erhalten die Audiospur durch den Aufruf der OT.initPublisher() Methode. Diese gibt eine Herausgeber Objekt zurück. Wir können die Methode .getAudioSource() auf dieses Objekt aufrufen, um ein MediaStreamTrack-Objekt zu erhalten.
Dieses MediaStream-Objekt enthält nun den Audiotrack des Herausgebers, den wir an Symbl.ai senden müssen. Wir werden die Web Audio API verwenden, um die Audiospur in einer Form zu manipulieren, die wir über WebSockets an Symbl.ai senden können. Damit die Web Audio API funktioniert, brauchen wir ein MediaStream Objekt. Es gibt eine API die es uns ermöglicht, das MediaStreamTrack-Objekt direkt zu verwenden, aber zum Zeitpunkt der Erstellung dieses Artikels ist sie nur für Firefox verfügbar.
const audioTrack = publisher.getAudioSource()
const stream = new MediaStream();
stream.addTrack(audioTrack);Jetzt haben wir das Stream-Objekt, das wir mit der Web Audio API verwenden können, um einen Audiopuffer zu erstellen, der an Symb.ai gesendet wird.
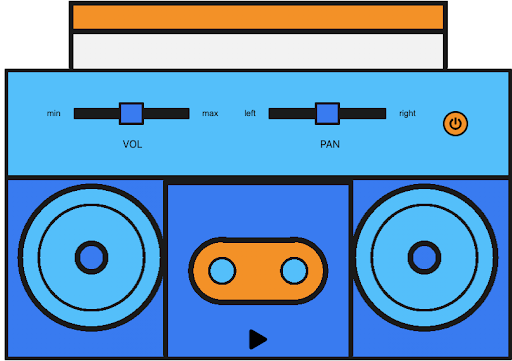
Zunächst ist es wichtig, die Web-Audio-API ein wenig zu verstehen, da wir sie zur Verarbeitung unserer Audiodaten auf dem Frontend verwenden werden. Stellen Sie sich die Web-Audio-API wie eine Gondel vor, in der wir jede einzelne Komponente deklarieren. Zuerst deklarieren wir das AudioContext-Objekt, das wie das äußere Gehäuse der Boombox ist.
const AudioContext = window.AudioContext;
const context = new AudioContext();Nachdem wir nun unseren Audiokontext deklariert haben, können wir ihm eine Quelle geben. Stellen Sie sich die Quelle als die Kassette oder CD vor, die in die Boombox eingelegt wird.
const source = context.createMediaStreamSource(stream);
const processor = context.createScriptProcessor(1024, 1, 1);
const gainNode = context.createGain();In diesen drei Codezeilen deklarieren wir zuerst unseren Quellknoten, dann unseren ScriptProcessorNodeund schließlich unseren `gainNode`. Keiner dieser drei Knoten macht im Moment etwas, weil wir sie nicht miteinander verbunden haben. Der `gainNode` ist wie der Lautstärkeregler an der Boombox und der Prozessorknoten ist wie das magnetische Lesegerät oder die Nadel, die die Daten von der Kassette oder CD liest.
Nun wollen wir sie miteinander verbinden.
source.connect(gainNode);
gainNode.connect(processor);
processor.connect(context.destination);Hier verbinden wir die Quelle mit dem `gainNode`. Wir können den `gainNode` verwenden, um die Lautstärke der Quelle zu erhöhen oder zu verringern. Wenn also, sagen wir mal, das Mikrofon einer Person zu leise ist, können wir den Wert der Verstärkung erhöhen, um das zu mildern.
gainNode.gain.value = 2;Das ist für dieses Tutorial nicht notwendig, da wir davon ausgehen, dass jeder ein ausreichendes Mikrofon hat.
Dann verbinden wir den Ausgang des `gainNode` mit dem Prozessorknoten. Der Prozessorknoten nimmt drei Argumente entgegen: die Puffergröße, die Anzahl der Eingangskanäle bzw. die Anzahl der Ausgangskanäle. Wir haben 1024 als Puffergröße gewählt, weil sie am unteren Ende des Sample-Frame-Spektrums liegt (256, 512, 1024, 2048, 4096, 8192, 16384). Das bedeutet, dass wir eine bessere Latenz/Leistung auf Kosten einer extrem genauen Audioqualität erhalten. Wenn Sie das Gefühl haben, dass Symbl.ai Wörter in Ihrem Audio vermisst, dann könnte eine Erhöhung dieses Wertes helfen. Beachten Sie, dass dies dazu führt, dass das onaudioprocess Ereignis häufiger aufgerufen wird, was Ihren Rechner verlangsamen könnte.
Apropos onaudioprocessDies ist das Ereignis, das ausgelöst wird, wenn der Prozessorknoten einen Audiopuffer mit der angegebenen Größe bereithält. Symbl.ai bereitet den Puffer zum Senden wie folgt vor:
processor.onaudioprocess = (e) => {
// convert to 16-bit payload
const inputData = e.inputBuffer.getChannelData(0) || new Float32Array(this.bufferSize);
const targetBuffer = new Int16Array(inputData.length);
for (let index = inputData.length; index > 0; index--) {
targetBuffer[index] = 32767 * Math.min(1, inputData[index]);
}
// Send audio stream to websocket.
if (ws.readyState === WebSocket.OPEN) {
ws.send(targetBuffer.buffer);
}
};
};
Wir werden später in diesem Artikel darüber sprechen, wie wir den Puffer mithilfe von WebSockets senden.
Schließlich leiten wir den Prozessorknoten an das Ziel zurück. Das Ziel ist wie die Lautsprecher der Boombox.
Das folgende Diagramm zeigt, was wir bisher mit der Web Audio API aufgebaut haben.
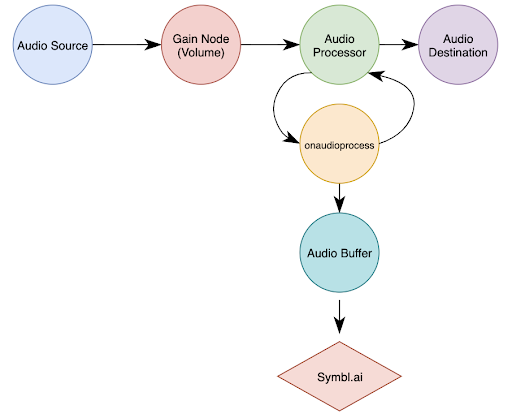
Und damit ist unsere Boombox einsatzbereit!
Erstellen wir nun eine WebSocket-Verbindung mit Symbl.ai, damit wir den in den vorherigen Schritten vorbereiteten Audiopuffer senden und die Erkenntnisse von Symbl.ai empfangen können.
const accessToken = accessToken;
const uniqueMeetingId = btoa("user@example.com");
const symblEndpoint = `wss://api.symbl.ai/v1/realtime/insights/${uniqueMeetingId}?access_token=${accessToken}`;Um das Access Token zu generieren, folgen Sie bitte dieser Anleitung.
Die eindeutige Besprechungs-ID kann ein beliebiger eindeutiger Hash oder eine beliebige Zeichenfolge sein. Dies ist nur ein Beispiel für die Erstellung einer eindeutigen verschlüsselten Zeichenfolge aus einer E-Mail. Lassen Sie uns nun unsere Zuhörer deklarieren.
// Fired when a message is received from the WebSocket server
ws.onmessage = (event) => {
// You can find the conversationId in event.message.data.conversationId;
const data = JSON.parse(event.data);
if (data.type === 'message' && data.message.hasOwnProperty('data')) {
console.log('conversationId', data.message.data.conversationId);
}
if (data.type === 'message_response') {
for (let message of data.messages) {
console.log('Transcript (more accurate): ', message.payload.content);
}
}
if (data.type === 'topic_response') {
for (let topic of data.topics) {
console.log('Topic detected: ', topic.phrases)
}
}
if (data.type === 'insight_response') {
for (let insight of data.insights) {
console.log('Insight detected: ', insight.payload.content);
}
}
if (data.type === 'message' && data.message.hasOwnProperty('punctuated')) {
console.log('Live transcript (less accurate): ', data.message.punctuated.transcript)
}
console.log(`Response type: ${data.type}. Object: `, data);
};
// Fired when the WebSocket closes unexpectedly due to an error or lost connection
ws.onerror = (err) => {
console.error(err);
};
// Fired when the WebSocket connection has been closed
ws.onclose = (event) => {
console.info('Connection to websocket closed');
};
Wir haben uns für die data.message.punctuated.transcript Taste, die eine Live-Transkription liefert. Dies geht auf Kosten einer gewissen Genauigkeit, aber Sie können entscheiden, wie Sie die Daten verwenden möchten. Wenn die WebSocket-Verbindung geöffnet wird, müssen wir eine Nachricht an Symbl.ai senden, in der wir unser Meeting und die beteiligten Sprecher beschreiben. Dies hilft uns bei der Erstellung einer Mitschrift nach der Besprechung, sowie bei anderen Dingen wie Tagebuchführung der Sprecher.
// Fired when the connection succeeds.
ws.onopen = (event) => {
ws.send(JSON.stringify({
type: 'start_request',
meetingTitle: 'Websockets How-to', // Conversation name
insightTypes: ['question', 'action_item'], // Will enable insight generation
config: {
confidenceThreshold: 0.5,
languageCode: 'en-US',
speechRecognition: {
encoding: 'LINEAR16',
sampleRateHertz: 44100,
}
},
speaker: {
userId: 'example@symbl.ai',
name: 'Example Sample',
}
}));
};
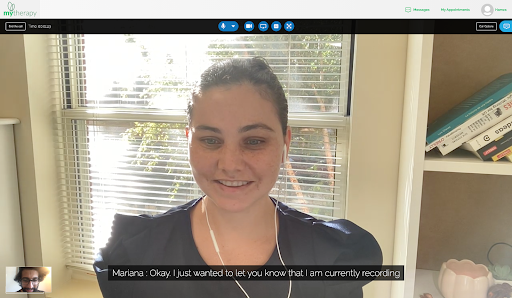
Und damit ist der Kern unserer Speech to Text-Demo fertig! Mit etwas UI-Arbeit sieht ein Anruf mit Sprachtranskription so aus:
Teilen Sie:
Hamza ist ein Software-Ingenieur aus Chicago. Er arbeitet bei Webrtc.ventures, einem führenden Unternehmen, das WebRTC-Lösungen anbietet. Er arbeitet auch als Full-Stack-Entwickler bei Vonage und hilft bei der Video-Plattform, um die Bedürfnisse der Kunden besser zu erfüllen. Als stolzer Introvertierter verbringt er seine freie Zeit am liebsten mit seinen Katzen.