
Teilen Sie:
Aaron war ein Entwickler-Befürworter bei Nexmo. Aaron ist ein erfahrener Software-Ingenieur und Möchtegern-Digitalkünstler, der häufig Dinge mit Code oder Elektronik entwickelt, manchmal auch beides. Wenn er an etwas Neuem arbeitet, erkennt man das in der Regel am Geruch von brennenden Bauteilen in der Luft.
Automatische Klassifizierung von Anrufaufzeichnungen mit NLP
Lesedauer: 3 Minuten
Die Voice API von Nexmo macht es einfach, ein- und ausgehende Telefongespräche aufzuzeichnen. Allerdings kann es sehr zeitaufwändig werden, jeden Anruf zu lokalisieren, bei dem ein bestimmtes Thema, wie z. B. "Informatik", diskutiert wird, wenn man sich jedes Mal jede Audiodatei anhören muss.
In diesem Tutorial zeigen wir Ihnen, wie Sie mit Hilfe von Natural Language Processing über Google Cloud Services den Inhalt jeder Aufzeichnung automatisch klassifizieren können, so dass Sie Sprachanrufe, die sich auf bestimmte Themen beziehen, schnell identifizieren können.
Der gesamte Code für dieses Tutorial ist auf GitHub verfügbar. Es verwendet pipenv zur Verwaltung von Abhängigkeiten und benötigt Python 3.6.4. Sie können eine virtuelle Umgebung erstellen und die Abhängigkeiten installieren, indem Sie pipenv ausführen:
pipenv installWir werden die Nexmo Voice API verwenden, insbesondere die record Aktion. Bevor Sie mit diesem Tutorial fortfahren, sollten Sie unsere Voice-Bausteine sowie einige unserer früheren Tutorials zur Erstellung von Voice Applications durchlesen.
Wir verwenden in diesem Tutorial auch zwei Google Cloud Services APIs: Cloud Speech-to-Text und Cloud Natural Language. Sie sollten ein neues Google Cloud Platform (GCP)-Projekt erstellen und sicherstellen, dass Sie Speech-to-Text und Natural Language aktivieren.
Denken Sie daran, Ihre GCP-Projektanmeldeinformationen herunterzuladen und sie an einem Ort zu speichern, an dem Ihr Skript darauf zugreifen kann. Ich habe meine in das Stammverzeichnis des Projekts eingefügt und sie benannt google_private.json.
Es gibt eine .env.example Datei im Stammverzeichnis des Projekts. In dieser Beispieldatei sind die verschiedenen Umgebungsvariablen aufgeführt, die die Anwendung erwartet. Kopieren Sie diese Datei und benennen Sie sie um in .env. Alle in dieser Datei festgelegten Werte werden automatisch in Ihre Umgebung geladen, wenn Sie die Anwendung ausführen:
pipenv shellAufzeichnung unseres Gesprächs
Hoffentlich sind Sie inzwischen vertraut mit NCCOs. Unsere erste Flask-Route wird unsere NCCO-Datei bereitstellen und die Nexmo Voice API anweisen, alle Anrufe an unsere virtuelle Nummer aufzuzeichnen:
@app.route("/", methods=["GET"])
def ncco():
logger.info(f"New call received from {request.args['from']}")
return jsonify(
[
{"action": "talk", "text": "Record your message after the beep"},
{
"action": "record",
"eventUrl": [f"{os.environ['BASE_URL']}/recordings"],
"format": "wav",
"endOnKey": "*",
"beepStart": True,
},
]
)Im obigen Code sind vor allem zwei Dinge zu beachten:
Die
event_urlzeigt auf unseren lokalen Flask-Server. Der Handler für diese Route wird im weiteren Verlauf des Tutorials besprochen.Das Aufnahmeformat ist eingestellt auf
wavNexmo stellt die Aufnahmen standardmäßig als MP3-Dateien zur Verfügung. Der Google Speech-to-Text-Dienst unterstützt jedoch WAV, daher müssen wir das Format unserer Aufnahme entsprechend einstellen.
Jedes Mal, wenn ein Anruf abgeschlossen wird, sendet die Nexmo Voice API eine POST Anfrage an unsere event_url. Ich habe die meiste Arbeit aus dem Flask View Handler herausgenommen und in eine Reihe von Hintergrundaufgaben mit Huey:
pipeline = download_recording_task.then(transcribe_audio).then(classify_transcription)
huey.enqueue(pipeline)
Die get_recording Methode auf dem Nexmo Python-Client ist neu, d.h. wenn Sie den Python-Client bereits installiert haben, müssen Sie wahrscheinlich ein Upgrade durchführen:
@huey.task()
def download_recording(recording_url, recording_uuid):
logger.info(f"Download recording {recording_uuid}")
recording = nexmo_client.get_recording(recording_url)
recordingfile = f"./recordings/{recording_uuid}.wav"
os.makedirs(os.path.dirname(recordingfile), exist_ok=True)
with open(recordingfile, "wb") as f:
f.write(recording)
return {"recording_uuid": recording_uuid}Nachdem Sie die WAV-Datei von Nexmo abgerufen haben, speichert die Anwendung sie in dem recordings Verzeichnis. Die Funktion download_recording Funktion gibt die recording_uuid innerhalb eines Wörterbuchs zurück, da Huey alle Rückgabewerte als Schlüsselwortargumente an die nächste Funktion in der Pipeline weitergibt.
Bevor wir den Inhalt unserer Audiodatei in natürlicher Sprache verarbeiten können, müssen wir sie in Text umwandeln:
@huey.task()
def transcribe_audio(*args, recording_uuid):
# Instantiates a client
client = speech.SpeechClient()
# The name of the audio file to transcribe
file_name = f"./recordings/{recording_uuid}.wav"
# Loads the audio into memory
with io.open(file_name, "rb") as audio_file:
content = audio_file.read()
audio = speech_types.RecognitionAudio(content=content)
config = speech_types.RecognitionConfig(
encoding=speech_enums.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US",
)
# Detects speech in the audio file
logger.info(f"Sending file {recording_uuid} for transcribing")
response = client.recognize(config, audio)
return {
"transcription_text": response.results[0].alternatives[0].transcript,
"recording_uuid": recording_uuid,
}Sie können mehr über die Google Cloud Speech-to-Text API auf deren Website. Nachdem die Audiodatei in Text umgewandelt wurde, wird die nächste Funktion in der Pipeline ausgelöst.
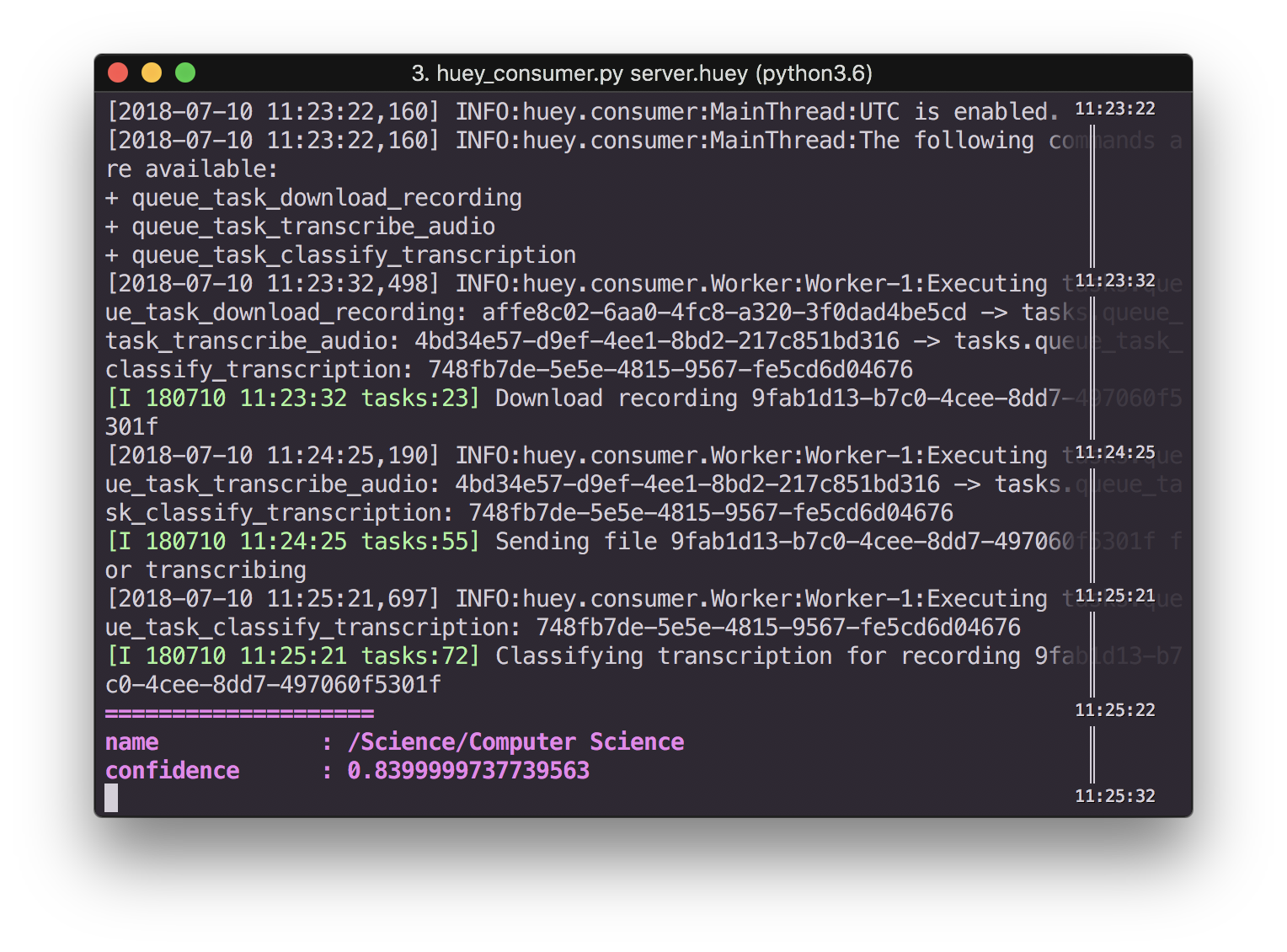 Screenshot of terminal showing audio classification
Screenshot of terminal showing audio classification
Die Anwendung führt einen letzten API-Aufruf durch, dieses Mal an den Google Cloud Language-Dienst:
@huey.task()
def classify_transcription(transcription_text, recording_uuid):
client = language.LanguageServiceClient()
document = language_types.Document(
content=transcription_text, type=language_enums.Document.Type.PLAIN_TEXT
)
logger.info(f"Classifying transcription for recording {recording_uuid}")
categories = client.classify_text(document).categories
for category in categories:
print(colorful.bold_violet("=" * 20))
print(colorful.bold_violet("{:<16}: {}".format("name", category.name)))
print(
colorful.bold_violet("{:<16}: {}".format("confidence", category.confidence))
)
return True
Diese API kann viel mehr als nur Text klassifizieren; sie kann Einblicke in die Stimmung des bereitgestellten Textes geben oder den Text mit Hilfe der Syntaktischen Analyse in eine Reihe von Sätzen und Token zerlegen. Lesen Sie die Dokumentation für weitere Details.
Wir hoffen, dass unser Tutorial Ihnen einen Eindruck davon vermittelt hat, was durch die Kombination der Nexmo Voice API mit Google Cloud möglich ist. Wenn Sie mehr über andere spannende Dinge erfahren möchten, die Sie mit der Nexmo Voice API erreichen können, werden diese anderen Tutorials für Sie interessant sein:
Teilen Sie:
Aaron war ein Entwickler-Befürworter bei Nexmo. Aaron ist ein erfahrener Software-Ingenieur und Möchtegern-Digitalkünstler, der häufig Dinge mit Code oder Elektronik entwickelt, manchmal auch beides. Wenn er an etwas Neuem arbeitet, erkennt man das in der Regel am Geruch von brennenden Bauteilen in der Luft.