
Teilen Sie:
Aboze Brain John ist ein Technology Business Analyst bei Axa Mansard. Er hat Erfahrung in den Bereichen Datenwissenschaft und -analyse, Produktforschung und technisches Schreiben. Brain war an End-to-End-Datenanalyseprojekten beteiligt, die von der Datenerfassung, -exploration, -umwandlung und -verflechtung über die Modellierung bis hin zur Ableitung verwertbarer Geschäftserkenntnisse reichten, und er bietet Wissensführerschaft.
SMS-Spam-Erkennung mit maschinellem Lernen in Python
Dieser Artikel wurde im April 2025 aktualisiert.
In diesem Lernprogramm werden Sie eine Webanwendung zur Erkennung von SMS-Spam erstellen. Diese Anwendung wird mit Python unter Verwendung des Flask-Frameworks erstellt und enthält ein maschinelles Lernmodell, das Sie trainieren werden, um SMS-Spam zu erkennen. Wir arbeiten mit der Vonage SMS API arbeiten, so dass Sie SMS-Nachrichten klassifizieren können, die an die in Ihrem Vonage Account registrierte Telefonnummer gesendet wurden.
Um eine virtuelle Rufnummer zu kaufen, gehen Sie zu Ihrem API-Dashboard und befolgen Sie die unten aufgeführten Schritte.
 Purchase a phone number
Purchase a phone number
Gehen Sie zu Ihrem API-Dashboard
Navigieren Sie zu BUILD & MANAGE > Numbers > Buy Numbers.
Wählen Sie die gewünschten Attribute und klicken Sie dann auf Suchen
Klicken Sie auf die Schaltfläche Kaufen neben der gewünschten Nummer und bestätigen Sie Ihren Kauf.
Um zu bestätigen, dass Sie die virtuelle Nummer erworben haben, gehen Sie im linken Navigationsmenü unter BUILD & MANAGE auf Numbers und dann auf Your Numbers
Python installiert. Die Anaconda Distribution enthält eine Reihe von nützlichen Bibliotheken für die Datenwissenschaft.
Grundkenntnisse in Flask, HTML und CSS.
Eine Übersicht über das Dateiverzeichnis für dieses Projekt finden Sie unten:
├── README.md
├── dataset
│ └── spam.csv
├── env
│ ├── bin
│ ├── etc
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
├── model
│ ├── spam_model.pkl
│ └── tfidf_model.pkl
├── notebook
│ └── project_notebook.ipynb
├── requirements.txt
├── script
└── web_app
├── app.py
├── static
└── templatesWir werden alle Dateien im obigen Verzeichnisbaum durch die Schritte dieses Tutorials erstellen.
Wir müssen eine isolierte Umgebung für verschiedene Python-Abhängigkeiten schaffen, die nur für dieses Projekt gelten.
Erstellen Sie zunächst einen neuen Entwicklungsordner. Führen Sie in Ihrem Terminal aus:
Als nächstes erstellen Sie eine neue virtuelle Python-Umgebung. Wenn Sie Anacondaverwenden, können Sie den folgenden Befehl ausführen:
Dann können Sie die Umgebung mit aktivieren:
Wenn Sie eine Standarddistribution von Python verwenden, erstellen Sie eine neue virtuelle Umgebung, indem Sie den folgenden Befehl ausführen:
Um die neue Umgebung auf einem Mac- oder Linux-Computer zu aktivieren, führen Sie aus:
Wenn Sie einen Windows-Computer verwenden, aktivieren Sie die Umgebung wie folgt:
Unabhängig von der Methode, die Sie zum Erstellen und Aktivieren der virtuellen Umgebung verwendet haben, sollte Ihre Eingabeaufforderung nun wie folgt aussehen:
Als Nächstes werden Sie alle Pakete installieren, die Sie für dieses Tutorial benötigen. Installieren Sie in Ihrer neuen Umgebung die folgenden Pakete (die Bibliotheken und Abhängigkeiten enthalten):
Hinweis: Um ein reproduzierbares Data-Science-Projekt zu erstellen, halten Sie sich an die Versionen, die ich hier aufgeführt habe. Dies waren die aktuellsten Versionen zum Zeitpunkt der Erstellung dieses Artikels.
Hier finden Sie einige Details zu diesen Paketen:
jupyterlab dient der Modellerstellung und Datenexploration.
flask dient der Erstellung des Anwendungsservers und der Seiten.
lightgbm ist der Algorithmus für maschinelles Lernen zur Erstellung unseres Modells
nexmo ist eine Python-Bibliothek für die Interaktion mit Ihrem Vonage Account
matplotlib, plotly, plotly-express sind für die Datenvisualisierung
python-dotenv ist ein Paket zur Verwaltung von Umgebungsvariablen wie API-Schlüsseln und anderen Konfigurationswerten.
nltk ist für natürlichsprachliche Operationen
numpy ist für die Berechnung von Arrays
pandas ist für die Bearbeitung und den Umgang mit strukturierten Daten gedacht.
regex ist für Operationen mit regulären Ausdrücken
scikit-learn ist ein Toolkit für maschinelles Lernen
Wortwolke wird verwendet, um Wortwolkenbilder aus Text zu erstellen
Starten Sie nach der Installation Ihr Jupyter-Labor durch Ausführen:
Dadurch wird die beliebte Jupyter-Laboroberfläche in Ihrem Webbrowser geöffnet, in der Sie einige interaktive Datenexplorationen und Modellbildungen durchführen werden.
Die Jupyter-Lab-Schnittstelle wird hier gezeigt Jupyterlab.
Nun, da Ihre Umgebung bereit ist, werden Sie die SMS-Trainingsdaten herunterladen und ein einfaches maschinelles Lernmodell zur Klassifizierung der SMS-Nachrichten erstellen. Der Spam-Datensatz für dieses Projekt kann heruntergeladen werden hier. Der Datensatz enthält 5574 Nachrichten mit den jeweiligen Kennzeichnungen Spam und Ham (legitim). Weitere Informationen über den Datensatz finden Sie hier. Mit diesen Daten werden wir ein maschinelles Lernmodell trainieren, das SMS korrekt als Ham oder Spam klassifizieren kann. Diese Verfahren werden in einem Jupyter-Notizbuch durchgeführt, das in unserem Dateiverzeichnis den Namen 'project_notebok' trägt.
Hier werden wir eine Reihe von Techniken anwenden, um die Daten zu analysieren und ein besseres Verständnis für sie zu bekommen.
Die notwendigen Bibliotheken für dieses Projekt können wie folgt in project_notebook.ipynb wie folgt importiert werden:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly_express as px
import wordcloud
import nltk
import warnings
warnings.filterwarnings('ignore')Der Spam-Datensatz, der sich im Datensatzverzeichnis spam.csv befindet, kann wie folgt importiert werden:
df = pd.read_csv("../dataset/spam.csv", encoding='latin-1')Hinweis: Die Zeichenkodierung dieses Datensatzes ist latin-1 (ISO/IEC 8859-1).
Als nächstes erhalten wir einen Überblick über den Datensatz:
df.head()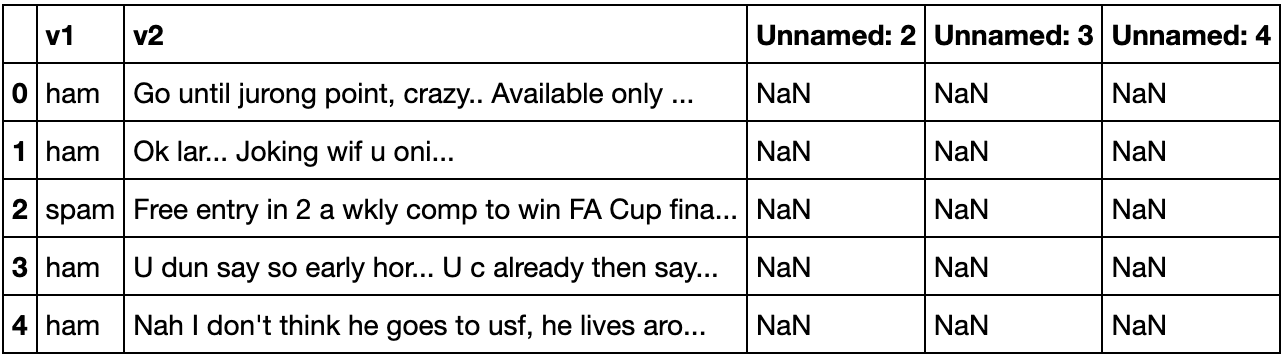 Dataset overview
Dataset overview
Der Datensatz enthält 5 Spalten. Spalte v1 ist die Bezeichnung des Datensatzes ("ham" oder "spam") und Spalte v2 enthält den Text der SMS-Nachricht. Die Spalten "Unbenannt: 2", "Unbenannt: 3" und "Unbenannt: 4" enthalten "NaN" (keine Zahl), was für fehlende Werte steht. Sie werden nicht benötigt und können daher gestrichen werden, da sie bei der Erstellung des Modells nicht von Nutzen sein werden. Mit dem folgenden Codeschnipsel werden die Spalten gelöscht und umbenannt, um die Verständlichkeit des Datensatzes zu verbessern:
df.drop(columns=['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], inplace=True)
df.rename(columns = {'v1':'class_label','v2':'message'},inplace=True)
df.head() Rename columns
Rename columns
Werfen wir einen Blick auf die Verteilung der Etiketten:
fig = px.histogram(df, x="class_label", color="class_label", color_discrete_sequence=["#871fff","#ffa78c"])
fig.show()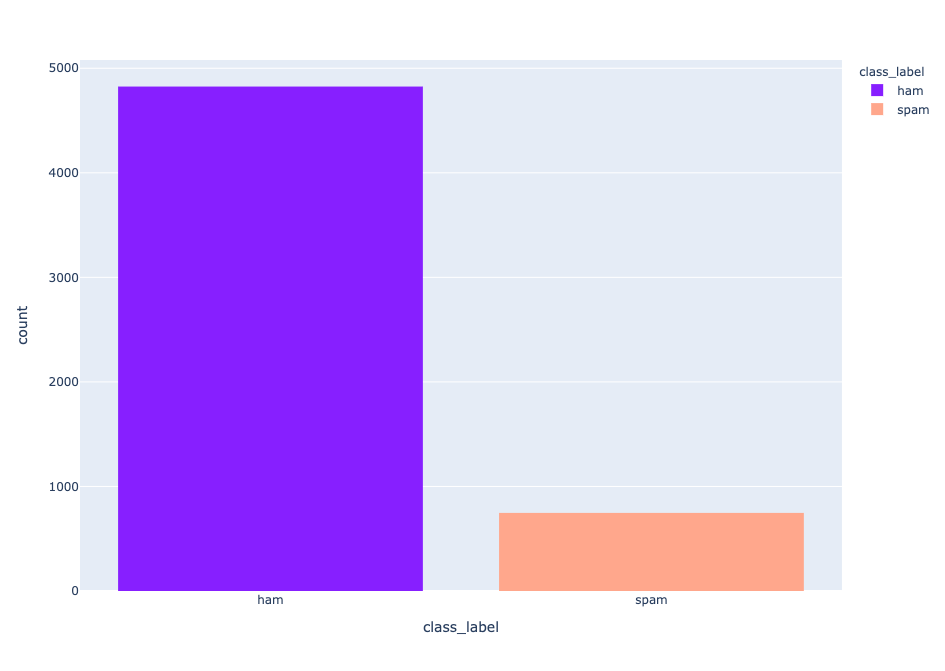 Distributions of labels
Distributions of labels
Wir haben einen unausgewogenen Datensatz, mit 747 Spam-Nachrichten und 4825 Ham-Nachrichten.
fig = px.pie(df.class_label.value_counts(),labels='index', values='class_label', color="class_label", color_discrete_sequence=["#871fff","#ffa78c"] )
fig.show()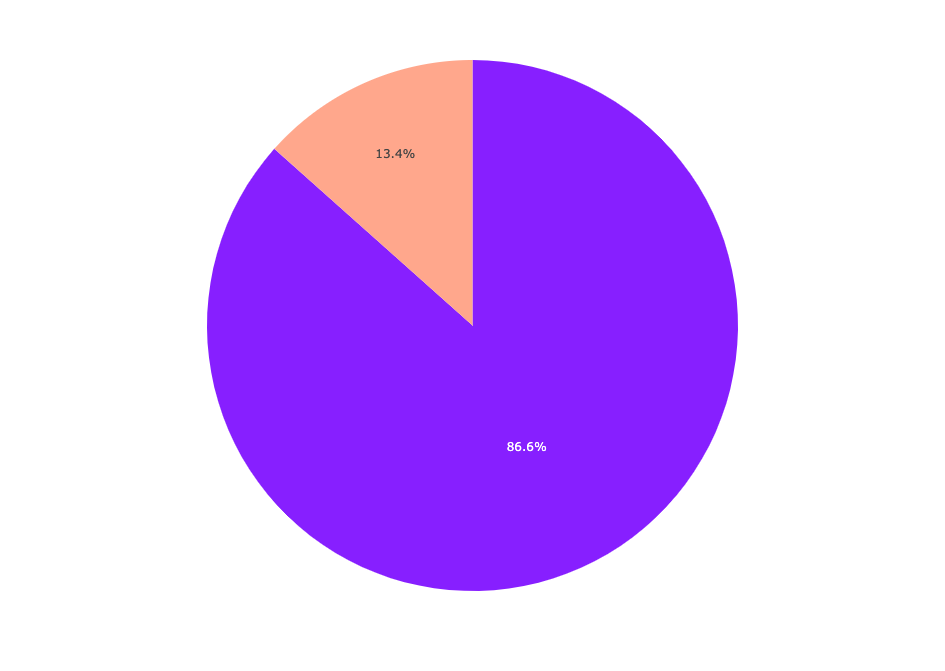 Labels pie chart
Labels pie chart
Der Spam macht 13,4 % des Datensatzes aus, während der Schinken 86,6 % des Datensatzes ausmacht.
Als Nächstes werden wir uns ein wenig mit dem Feature Engineering beschäftigen. Die Länge der Nachrichten könnte einige Einblicke geben. Schauen wir uns das mal an:
df['length'] = df['message'].apply(len)
df.head() Message length
Message length
fig = px.histogram(df, x="length", color="class_label", color_discrete_sequence=["#871fff","#ffa78c"] )
fig.show()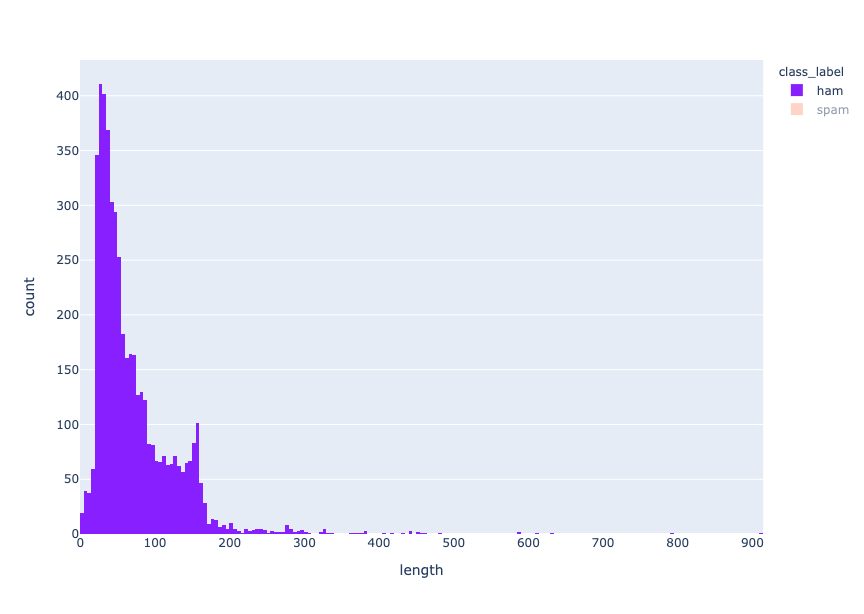 length distribution - ham
length distribution - ham
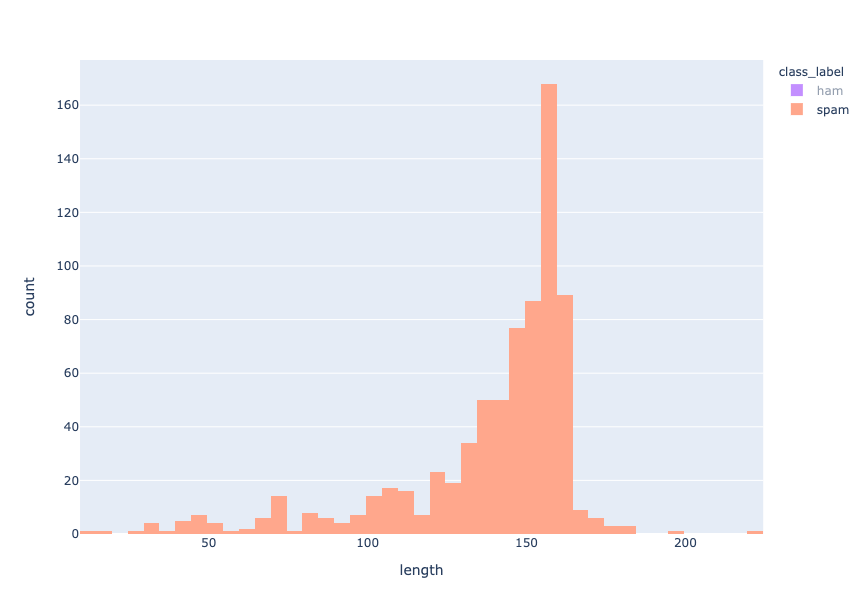 Length distribution - spam
Length distribution - spam
Es ist zu erkennen, dass Ham-Nachrichten kürzer sind als Spam-Nachrichten, da die Verteilung der Ham- und Spam-Nachrichtenlängen um 30-40 bzw. 155-160 Zeichen zentriert ist.
Eine Übersicht über die am häufigsten in Spam und Spam verwendeten Wörter hilft uns, den Datensatz besser zu verstehen. Eine Wortwolke kann Ihnen eine Vorstellung davon vermitteln, welche Art von Wörtern in jeder Klasse dominiert.
Um eine Wortwolke zu erstellen, trennen Sie zunächst die Klassen in zwei Pandas-Datenrahmen und fügen eine einfache Wortwolkenfunktion hinzu, wie unten gezeigt:
data_ham = df[df['class_label'] == "ham"].copy()
data_spam = df[df['class_label'] == "spam"].copy()
def show_wordcloud(df, title):
text = ' '.join(df['message'].astype(str).tolist())
stopwords = set(wordcloud.STOPWORDS)
fig_wordcloud = wordcloud.WordCloud(stopwords=stopwords, background_color="#ffa78c",
width = 3000, height = 2000).generate(text)
plt.figure(figsize=(15,15), frameon=True)
plt.imshow(fig_wordcloud)
plt.axis('off')
plt.title(title, fontsize=20)
plt.show()Im Folgenden finden Sie den Code, der eine Wortwolke für Spam-SMS anzeigt:
show_wordcloud(data_spam, "Spam messages") word cloud spam
word cloud spam
Sie können die Wortwolke auch für Schinken-SMS anzeigen:
show_wordcloud(data_ham, "ham messages")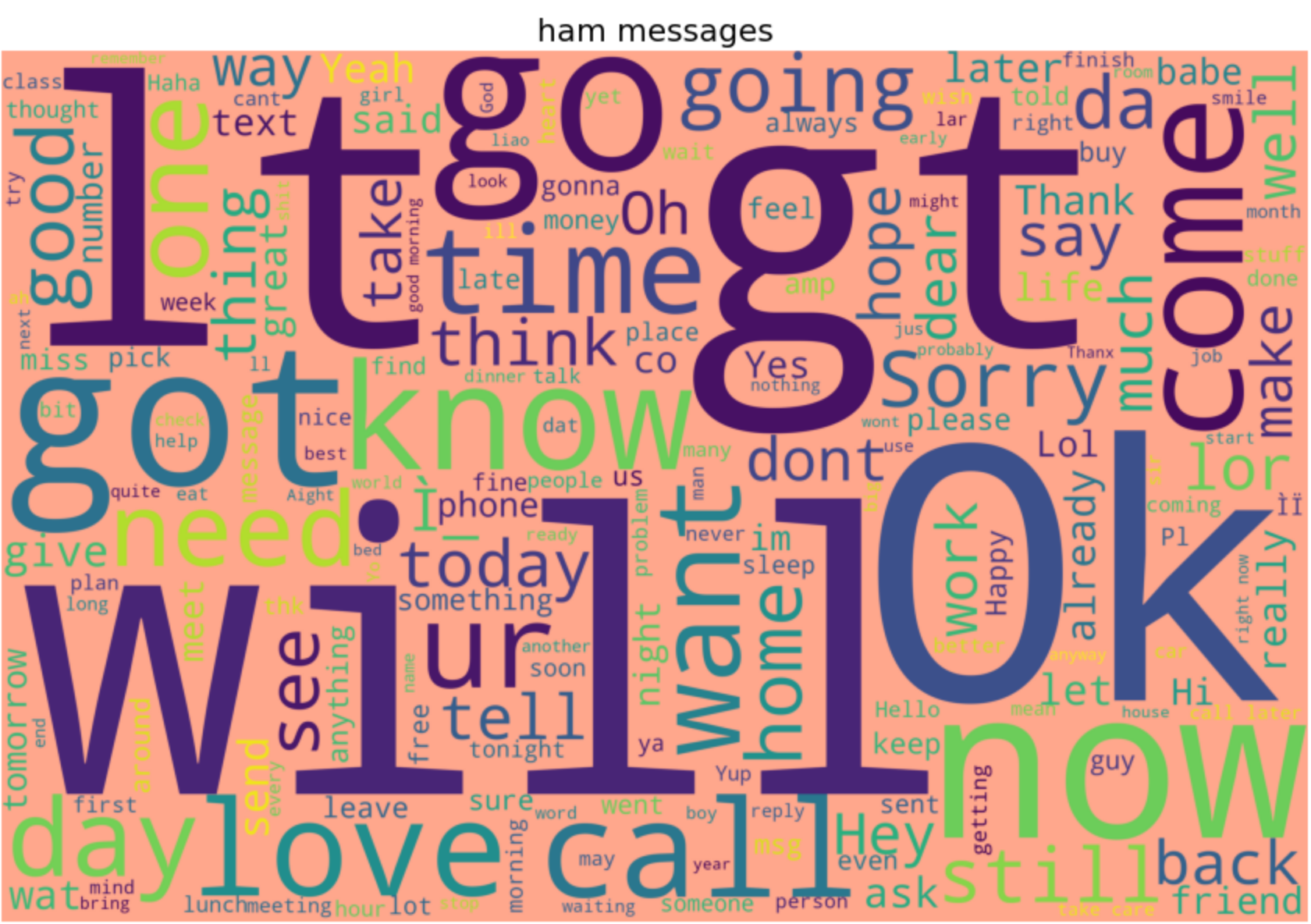 word cloud ham
word cloud ham
Der Prozess der Konvertierung von Daten in etwas, das ein Computer verstehen kann, wird als Pre-Processing bezeichnet. Im Zusammenhang mit diesem Artikel geht es um Prozesse und Techniken zur Vorbereitung unserer Textdaten für unseren Algorithmus für maschinelles Lernen
Zunächst werden wir die Beschriftung in eine numerische Form umwandeln. Dies ist vor dem Modelltraining unerlässlich, da Deep-Learning-Modelle Daten in numerischer Form benötigen.
df['class_label'] = df['class_label'].map( {'spam': 1, 'ham': 0})Als Nächstes werden wir den Inhalt der Nachricht mit regulären Ausdrücken (Regex) verarbeiten, um E-Mail- und Webadressen, Telefonnummern und Zahlen einheitlich zu halten, Symbole zu kodieren, Satzzeichen und Leerzeichen zu entfernen und schließlich den gesamten Text in Kleinbuchstaben umzuwandeln:
# Replace email address with 'emailaddress'
df['message'] = df['message'].str.replace(r'^.+@[^\.].*\.[a-z]{2,}$', 'emailaddress')
# Replace urls with 'webaddress'
df['message'] = df['message'].str.replace(r'^http\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(/\S*)?$', 'webaddress')
# Replace money symbol with 'money-symbol'
df['message'] = df['message'].str.replace(r'£|\$', 'money-symbol')
# Replace 10 digit phone number with 'phone-number'
df['message'] = df['message'].str.replace(r'^\(?[\d]{3}\)?[\s-]?[\d]{3}[\s-]?[\d]{4}$', 'phone-number')
# Replace normal number with 'number'
df['message'] = df['message'].str.replace(r'\d+(\.\d+)?', 'number')
# remove punctuation
df['message'] = df['message'].str.replace(r'[^\w\d\s]', ' ')
# remove whitespace between terms with single space
df['message'] = df['message'].str.replace(r'\s+', ' ')
# remove leading and trailing whitespace
df['message'] = df['message'].str.replace(r'^\s+|\s*?$', ' ')
# change words to lower case
df['message'] = df['message'].str.lower()Künftig werden wir Stoppwörter aus dem Inhalt der Nachricht entfernen. Stoppwörter sind Wörter, die Suchmaschinen programmiert haben, um sie zu ignorieren, sowohl bei der Indizierung von Einträgen für die Suche als auch beim Abruf als Ergebnis einer Suchanfrage, wie z. B. "der", "ein", "an", "in", "aber", "weil" usw.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
df['message'] = df['message'].apply(lambda x: ' '.join(term for term in x.split() if term not in stop_words))Als Nächstes werden wir die Grundform der Wörter extrahieren, indem wir die Affixe entfernen. Dies wird als "Stemming" bezeichnet, da die Äste eines Baumes bis auf die Stämme reduziert werden können. Es gibt zahlreiche Stemming-Algorithmen, wie z. B.:
Porter's Stemmer-Algorithmus
Lovins Stemmer
Dawson Stemmer
Krovetz Stemmer
Xerox Stemmer
N-Gramm Stemmer
Schneeball Stemmer
Lancaster Stemmer
Einige dieser Stemming-Algorithmen sind aggressiv und dynamisch. Einige gelten auch für andere Sprachen als Englisch, und die Größe der Textdaten wirkt sich auf die verschiedenen Effizienzstufen aus. Für diesen Artikel wurde der Snowball Stemmer aufgrund seiner Rechengeschwindigkeit verwendet.
Hinweis: Achten Sie bei der Verwendung dieser Stemming-Algorithmen darauf, dass Sie weder zu viel noch zu wenig Steming verwenden.
ss = nltk.SnowballStemmer("english")
df['message'] = df['message'].apply(lambda x: ' '.join(ss.stem(term) for term in x.split()))Algorithmen für maschinelles Lernen können nicht direkt mit Rohtext arbeiten. Der Text muss in Numbers umgewandelt werden - genauer gesagt, in Zahlenvektoren. Zerlegen wir die Nachrichten (Textdaten in Sätzen) in Wörter. Dies ist eine Voraussetzung für die Verarbeitung natürlicher Sprache, bei der jedes Wort erfasst und einer weiteren Analyse unterzogen werden muss. Zunächst erstellen wir ein Bag of Words (BOW)-Modell, um Merkmale aus dem Text zu extrahieren:
sms_df = df['message']
from nltk.tokenize import word_tokenize
# creating a bag-of-words model
all_words = []
for sms in sms_df:
words = word_tokenize(sms)
for w in words:
all_words.append(w)
all_words = nltk.FreqDist(all_words)Werfen wir einen Blick auf die Gesamtzahl der Wörter:
print('Number of words: {}'.format(len(all_words))) Number of words 6526
Number of words 6526
Stellen Sie nun die 10 häufigsten Wörter in den Textdaten dar:
all_words.plot(10, title='Top 10 Most Common Words in Corpus');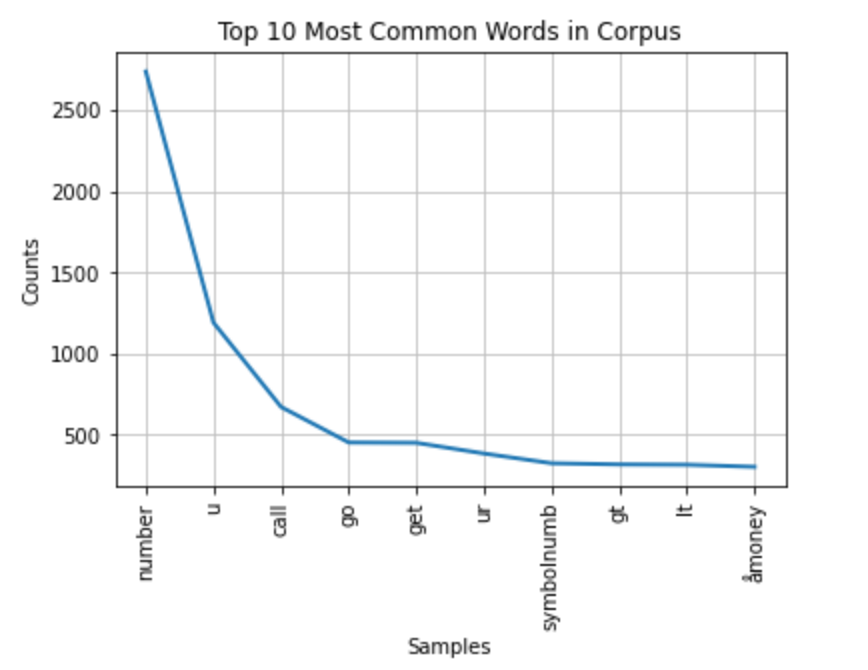 Most common words
Most common words
Als Nächstes werden wir eine NLP-Technik anwenden, um zu bewerten, wie wichtig Wörter in den Textdaten sind. Kurz gesagt, diese Technik definiert einfach, was ein "relevantes Wort" ist. Das mit dieser NLP-Technik erstellte tfidf_model wird auf der lokalen Festplatte gespeichert (serialisiert), um später die Testdaten für unsere Webanwendung zu transformieren:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_model = TfidfVectorizer()
tfidf_vec=tfidf_model.fit_transform(sms_df)
import pickle
#serializing our model to a file called model.pkl
pickle.dump(tfidf_model, open("../model/tfidf_model.pkl","wb"))
tfidf_data=pd.DataFrame(tfidf_vec.toarray())
tfidf_data.head() tfidf
tfidf
Die Form des resultierenden Datenrahmens ist 5572 x 6506. Um die Leistung unseres maschinellen Lernmodells zu trainieren und zu validieren, müssen wir die Daten in einen Trainings- und einen Testdatensatz aufteilen. Der Trainingsdatensatz sollte später in einen Trainings- und einen Validierungsdatensatz aufgeteilt werden.
### Separating Columns
df_train = tfidf_data.iloc[:4457]
df_test = tfidf_data.iloc[4457:]
target = df['class_label']
df_train['class_label'] = target
Y = df_train['class_label']
X = df_train.drop('class_label',axis=1)
# splitting training data into train and validation using sklearn
from sklearn import model_selection
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,Y,test_size=.2, random_state=42)Der Splitanteil für die Validierungsmenge beträgt 20 % der Trainingsdaten.
Wir werden einen Algorithmus für maschinelles Lernen verwenden, der als LightGBM bekannt ist. Es handelt sich um ein Gradient-Boosting-Framework, das baumbasierte Lernalgorithmen verwendet. Er hat die folgenden Vorteile:
Schnelleres Trainingstempo und höhere Effizienz
Geringere Speichernutzung
Bessere Genauigkeit
Unterstützung von parallelem und GPU-Lernen
Fähigkeit zur Verarbeitung großer Datenmengen
Die Leistungsmetrik für dieses Projekt ist die F1-Punktzahl. Diese Metrik berücksichtigt sowohl die Genauigkeit als auch die Wiederauffindbarkeit, um die Punktzahl zu berechnen. Die F1-Punktzahl erreicht ihren besten Wert bei 1 und ihren schlechtesten Wert bei 0.
import lightgbm as lgb
from sklearn.metrics import f1_score
def train_and_test(model, model_name):
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f'F1 score is: {f1_score(pred, y_test)}')
for depth in [1,2,3,4,5,6,7,8,9,10]:
lgbmodel = lgb.LGBMClassifier(max_depth=depth, n_estimators=200, num_leaves=40)
print(f"Max Depth {depth}")
print(" ")
print(" ")
train_and_test(lgbmodel, "Light GBM") F1 score
F1 score
Aus dieser Iteration geht hervor, dass die maximale Tiefe von sechs (6) den höchsten F1-Wert von 0,9285714285714285 hat. Wir werden weiterhin eine zufällige Rastersuche nach den besten Parametern für das Modell durchführen:
from sklearn.model_selection import RandomizedSearchCV
lgbmodel_bst = lgb.LGBMClassifier(max_depth=6, n_estimators=200, num_leaves=40)
param_grid = {
'num_leaves': list(range(8, 92, 4)),
'min_data_in_leaf': [10, 20, 40, 60, 100],
'max_depth': [3, 4, 5, 6, 8, 12, 16, -1],
'learning_rate': [0.1, 0.05, 0.01, 0.005],
'bagging_freq': [3, 4, 5, 6, 7],
'bagging_fraction': np.linspace(0.6, 0.95, 10),
'reg_alpha': np.linspace(0.1, 0.95, 10),
'reg_lambda': np.linspace(0.1, 0.95, 10),
"min_split_gain": [0.0, 0.1, 0.01],
"min_child_weight": [0.001, 0.01, 0.1, 0.001],
"min_child_samples": [20, 30, 25],
"subsample": [1.0, 0.5, 0.8],
}
model = RandomizedSearchCV(lgbmodel_bst, param_grid, random_state=1)
search = model.fit(X_train, y_train)
search.best_params_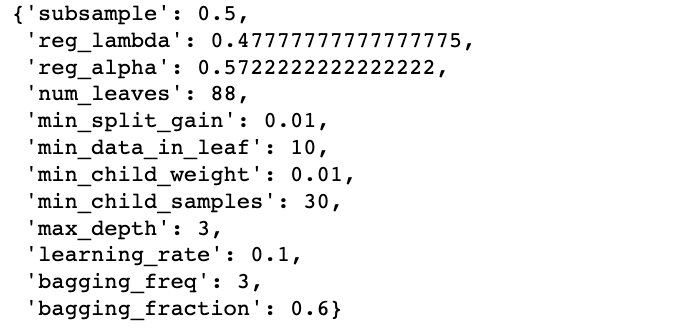 best parameters search
best parameters search
Wir werden die besten Parameter verwenden, um das Modell zu trainieren:
best_model = lgb.LGBMClassifier(subsample=0.5,
reg_lambda= 0.47777777777777775,
reg_alpha= 0.5722222222222222,
num_leaves= 88,
min_split_gain= 0.01,
min_data_in_leaf= 10,
min_child_weight= 0.01,
min_child_samples= 30,
max_depth= 3,
learning_rate= 0.1,
bagging_freq= 3,
bagging_fraction= 0.6,
random_state=1)
best_model.fit(X_train,y_train) Trained model
Trained model
Überprüfen wir die Leistung des Modells anhand seiner Vorhersage:
prediction = best_model.predict(X_test)
print(f'F1 score is: {f1_score(prediction, y_test)}') Model prediction
Model prediction
In einem letzten Schritt führen wir ein vollständiges Training mit dem Datensatz durch, damit unsere Webanwendung Vorhersagen für Daten machen kann, die sie noch nicht gesehen hat. Wir speichern das Modell auf unserem lokalen Rechner:
best_model.fit(tfidf_data, target)
pickle.dump(best_model, open("../model/spam_model.pkl","wb"))
Nun, da Sie das trainierte Modell haben, werden wir eine Flask-Anwendung erstellen, die über die Vonage SMS API gesendete und empfangene Nachrichten liest und sie als Spam oder Ham klassifiziert. Das Endergebnis wird in einem SMS-Dashboard angezeigt, das Sie ebenfalls in diesem Abschnitt definieren werden.
Das Verzeichnis web_app Verzeichnis besteht aus:
├── app.py
├── static
│ ├── Author.png
│ ├── style.css
│ ├── style2.css
│ └── vonage_logo.svg
└── templates
├── inbox.html
├── index.html
└── predict.htmlÖffnen Sie in Ihrem Code-Editor eine neue Datei mit dem Namen .env (beachten Sie den führenden Punkt) und fügen Sie die folgenden Anmeldedaten hinzu:
API_KEY=<Your API key>
API_SECRET=<Your API secret>
Dies ist aus Sicherheitsgründen wichtig, da Sie Ihre Geheimnisse niemals fest in Ihre Anwendung codieren sollten.
Als nächstes erstellen wir eine Datei namens app.py in dem Verzeichnis web_app Verzeichnis. Wir werden Bibliotheken importieren, um die Webanwendung erfolgreich zu erstellen. Anschließend laden wir unsere Vonage-API-Anmeldedaten aus der Datei .env Datei und starten die Flask-Anwendung. Außerdem importieren wir die gespeicherten Modelle aus unserem Notizbuch.
import os
import warnings
import nexmo
from flask import Flask, render_template, url_for, request, session
import pickle
import pandas as pd
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from dotenv import load_dotenv
load_dotenv()
API_KEY = os.getenv("API_KEY")
API_SECRET = os.getenv("API_SECRET")
client = nexmo.Client(key=API_KEY, secret=API_SECRET)
warnings.filterwarnings("ignore")
app = Flask(__name__)
# secret key is needed for session
app.secret_key = os.getenv('SECRET_KEY')Nach der Flask-Anwendungsinstanz verwenden wir Flask-Sitzungen, um die Datenaufbewahrung in verschiedenen Serverprotokollierungsintervallen zu unterstützen. Für diese Sitzungen benötigen Sie einen geheimen Schlüssel - Sie können den Wert des geheimen Schlüssels in der Datei .env Datei speichern und laden, wie wir es mit den API-Anmeldeinformationen getan haben.
Als Nächstes definieren wir drei Funktionen im Zusammenhang mit Routen: home(), inbox(), und predict(). Die entsprechenden Vorlagen für diese Routen sind index.html, inbox.html, und predict.html, gestylt mit zwei Stylesheets, stlye.css und stlye2.css.
Die Home/Index-Route stellt die Schnittstelle zum Senden der Nachricht bereit:
@app.route('/', methods=['GET', 'POST'])
def home():
return render_template('index.html')Die Schnittstelle ist unten dargestellt:
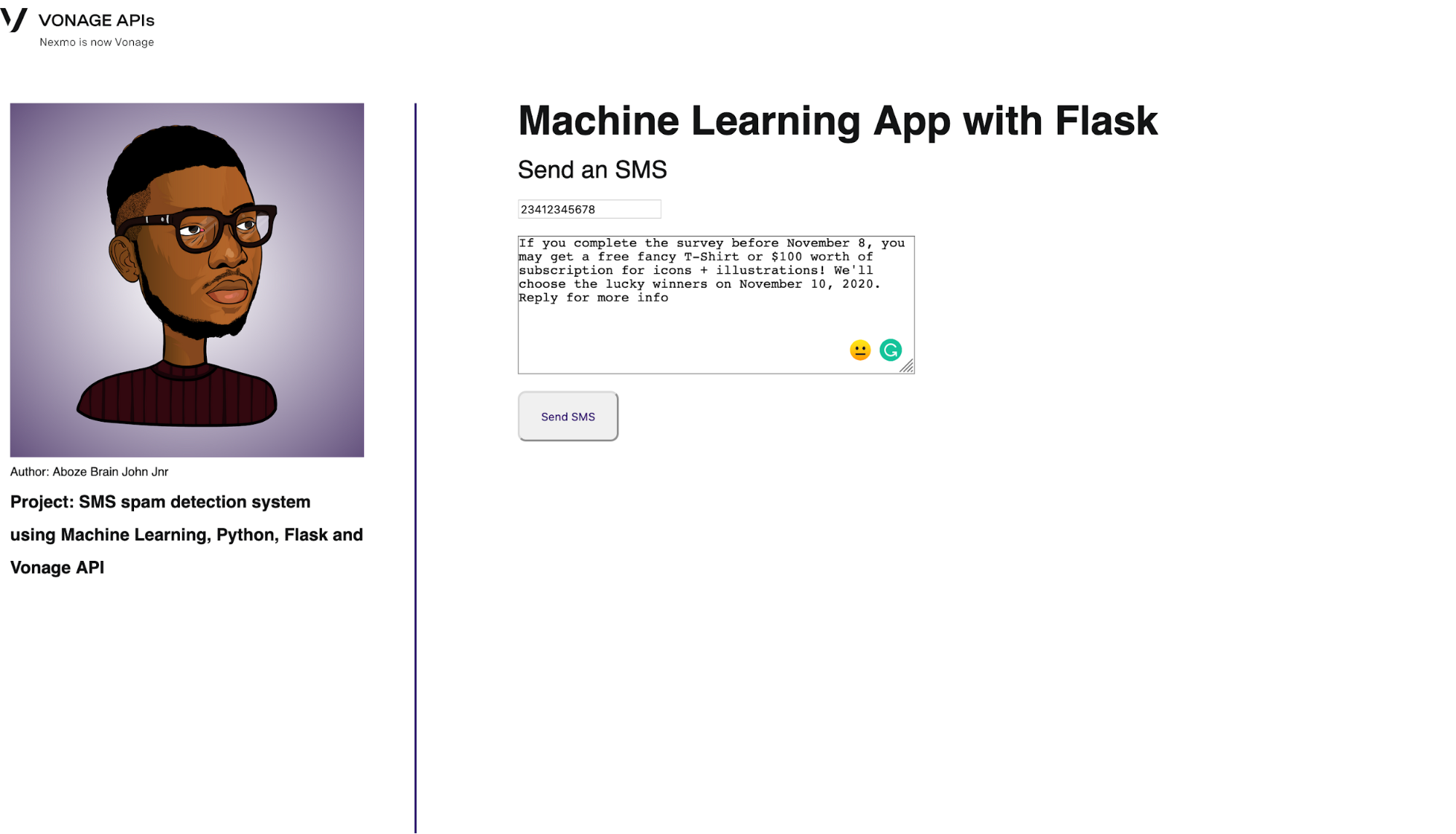 Home interface
Home interface
Die unterstützende index.html Datei im Verzeichnis templates Verzeichnis sollte wie folgt aussehen:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Spam detection Project</title>
<link rel="stylesheet" href="../static/style.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main">
<h1>Machine Learning App with Flask</h1>
<p>Send an SMS</p>
<form action="/inbox" method="POST">
<input id="to_number" class="form-control" name="to_number" type="tel" placeholder="Phone Number"/>
<br>
<br>
<textarea id="message" class="form-control" name="message" placeholder="Your text message goes here" rows="10" cols="50"></textarea>
<br>
<br>
<input type="submit" class="btn-info" value="Send SMS">
</form>
</div>
</section>
</body>
</html>
Die nächste Route ist die Posteingangsroute, in der die gesendeten Nachrichten und die Absendertelefonnummer aus dem Index gespeichert werden. Die Vonage SMS API wird hier verwendet, um das Client-Objekt zu initiieren und die Nachricht zu senden:
@app.route('/inbox', methods=['GET', 'POST'])
def inbox():
""" A POST endpoint that sends an SMS. """
# Extract the form values:
to_number = request.form['to_number']
message = request.form['message']
session['to_number'] = to_number
session['message'] = message
# Send the SMS message:
result = client.send_message({
'from': 'Vonage APIs',
'to': to_number,
'text': message,
})
return render_template('inbox.html', number=to_number, msg=message)Die Schnittstelle ist unten dargestellt:
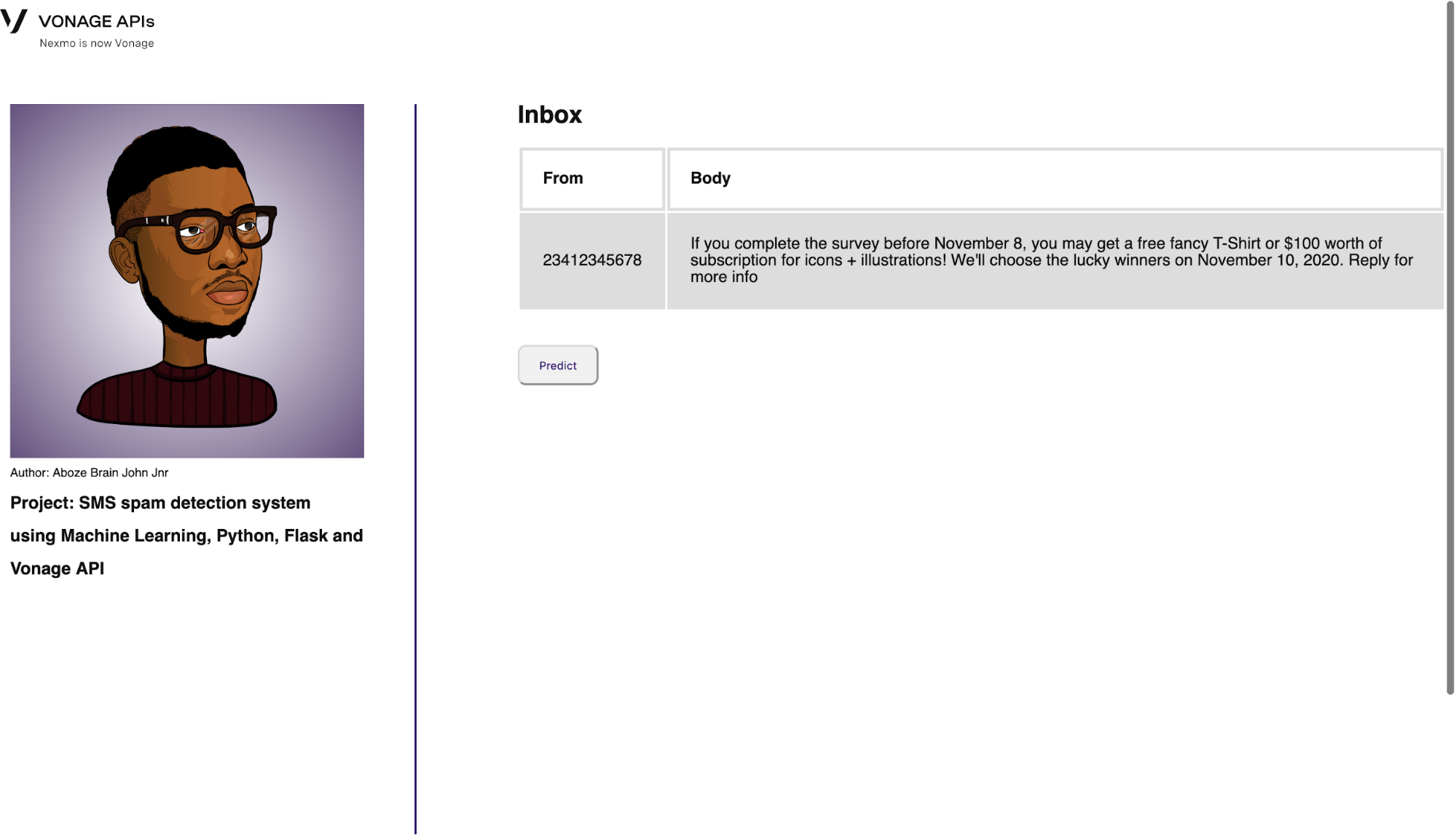 Inbox interface
Inbox interface
Die unterstützende inbox.html Datei im Verzeichnis templates Verzeichnis sieht wie folgt aus:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Prediction</title>
<link rel="stylesheet" href="../static/style2.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main">
<h1>Inbox</h1>
<br>
<table class="table" >
<tr>
<th scope="col">From</th>
<th scope="col">Body</th>
</tr>
<tr scope='row'>
<td>{{number}}</td>
<td>{{msg}}</td>
</tr>
</table>
<br>
<br>
<form action="/predict" method="POST">
<input type="submit" class="btn-info" value="Predict">
</form>
<!-- <input type="submit" class="btn-info" value="Predict" formaction="/predict" method="POST"> -->
</div>
</section>
</body>
</html>
Der letzte Weg ist für unsere Vorhersage. Dabei werden alle vorherigen Vorverarbeitungstechniken, die zum Trainieren des maschinellen Lernmodells verwendet wurden, auf die neuen Daten in Form von Posteingangsnachrichten angewendet:
@app.route('/predict', methods=['POST'])
def predict():
model = pickle.load(open("../model/spam_model.pkl", "rb"))
tfidf_model = pickle.load(open("../model/tfidf_model.pkl", "rb"))
if request.method == "POST":
message = session.get('message')
message = [message]
dataset = {'message': message}
data = pd.DataFrame(dataset)
data["message"] = data["message"].str.replace(
r'^.+@[^\.].*\.[a-z]{2,}$', 'emailaddress')
data["message"] = data["message"].str.replace(
r'^http\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(/\S*)?$', 'webaddress')
data["message"] = data["message"].str.replace(r'£|\$', 'money-symbol')
data["message"] = data["message"].str.replace(
r'^\(?[\d]{3}\)?[\s-]?[\d]{3}[\s-]?[\d]{4}$', 'phone-number')
data["message"] = data["message"].str.replace(r'\d+(\.\d+)?', 'number')
data["message"] = data["message"].str.replace(r'[^\w\d\s]', ' ')
data["message"] = data["message"].str.replace(r'\s+', ' ')
data["message"] = data["message"].str.replace(r'^\s+|\s*?$', ' ')
data["message"] = data["message"].str.lower()
stop_words = set(stopwords.words('english'))
data["message"] = data["message"].apply(lambda x: ' '.join(
term for term in x.split() if term not in stop_words))
ss = nltk.SnowballStemmer("english")
data["message"] = data["message"].apply(lambda x: ' '.join(ss.stem(term)
for term in x.split()))
# tfidf_model = TfidfVectorizer()
tfidf_vec = tfidf_model.transform(data["message"])
tfidf_data = pd.DataFrame(tfidf_vec.toarray())
my_prediction = model.predict(tfidf_data)
return render_template('predict.html', prediction=my_prediction)Die Schnittstelle ist unten dargestellt:
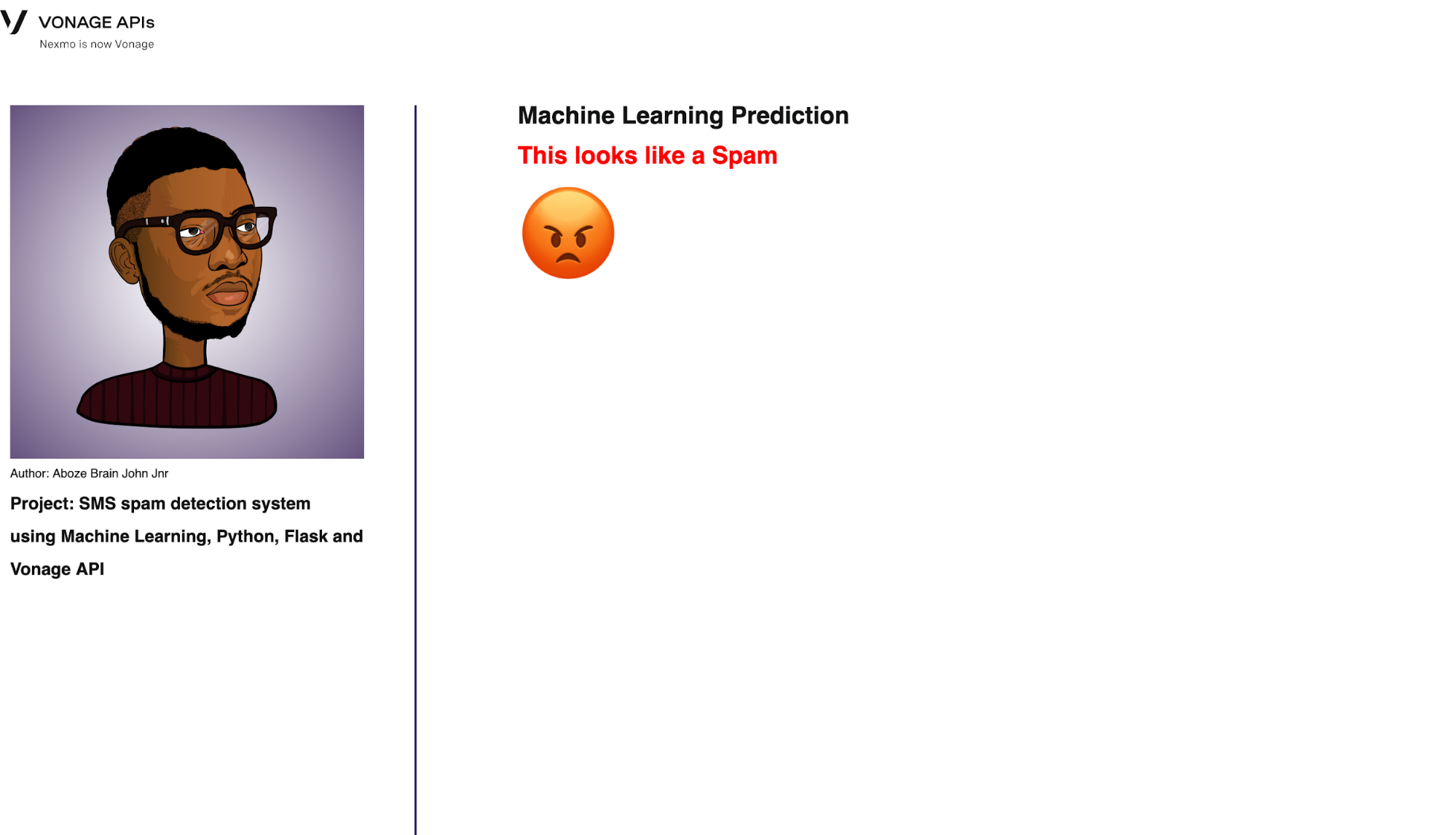 Prediction interface
Prediction interface
Die unterstützende predict.html Datei im Verzeichnis templates Verzeichnis sieht wie folgt aus:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Prediction</title>
<link rel="stylesheet" href="../static/style2.css">
</head>
<body>
<nav>
<img src="{{url_for('static', filename='vonage_logo.svg')}}">
</nav>
<section>
<div class="side">
<img src="{{url_for('static', filename='Author.png')}}" width="350px" height="350px">
<h4>Author: Aboze Brain John Jnr</h4>
<h2>Project: SMS spam detection system</h2>
<h2>using Machine Learning, Python, Flask and</h2>
<h2>Vonage API</h2>
</div>
<div class="vl"></div>
<div class="main results">
<h1>Machine Learning Prediction</h1>
{% if prediction == 1%}
<h2 style="color:red; font-size: x-large;">This looks like a Spam</h2>
<span style='font-size:100px;'>😡</span>
{% elif prediction == 0%}
<h2 style="color:green; font-size: x-large;">This looks like a Ham</h2>
<span style='font-size:100px;'>😀</span>
{% endif %}
</div>
</section>
</body>
</html>
Fügen Sie am Ende der Python-Datei diesen Code ein, um einen lokalen Server zu starten:
if __name__ == '__main__':
app.run(debug=True)Nachfolgend finden Sie das minimierte CSS für die beiden unterstützenden Stylesheets, die in diesem Projekt verwendet werden.
Für style.css:
*{box-sizing:border-box;padding:0;margin:0}body{color:#131415;font-family:spezia,sans-serif}nav{position:sticky;padding-top:10px}section{display:flex;flex-wrap:nowrap;padding:50px 10px}section h4{font-size:12px;font-weight:400;padding-top:5px}section h2{font-size:17px;font-weight:700;padding-top:15px}.vl{border-left:2px solid #310069;margin-left:50px;height:100vh}.main{margin-left:100px}.main h1{font-size:40px;padding-bottom:15px}.main p{font-size:24px;padding-bottom:15px}.btn-info{color:#310069;height:50px;width:100px;border-radius:8px}Für style2.css:
*{box-sizing:border-box;padding:0;margin:0}body{color:#131415;font-family:spezia,sans-serif}nav{position:sticky;padding-top:10px}section{display:flex;flex-wrap:nowrap;padding:50px 10px}section h4{font-size:12px;font-weight:400;padding-top:5px}section h2{font-size:17px;font-weight:700;padding-top:15px}.vl{border-left:2px solid #310069;margin-left:50px;height:100vh}.main{margin-left:100px}td,th{border:3px solid #ddd;text-align:left;padding:20px}tr:nth-child(even){background-color:#ddd}input{width:80px;height:40px;border-radius:8px;color:#310069}button{width:80px;height:40px;border-radius:8px;color:#310069}Jetzt können Sie Ihre Anwendung testen! Um Ihren Server zu starten, öffnen Sie Ihren Stammordner in einem Terminal und führen Sie dann Folgendes im web_app Verzeichnis aus:
Wenn Sie alle oben genannten Schritte befolgt haben, sollte Ihr Server wie unten abgebildet laufen:
 Server output
Server output
Geben Sie http://localhost:5000/ in die Adressleiste ein, um eine Verbindung mit der Anwendung herzustellen.
Damit sind wir am Ende dieses Tutorials angelangt. Sie können andere SMS-Beispiele ausprobieren, um das Ergebnis zu sehen. Ich bin mir sicher, dass Sie sich bereits all die erstaunlichen Möglichkeiten und Anwendungsfälle für dieses neue Wissen vorstellen können. Sie können diese Spam-Filterung in HR-Software, Chatbots, Kundenservice und jede andere nachrichtenbasierte Anwendung integrieren.
Haben Sie eine Frage oder möchten Sie uns mitteilen, was Sie gerade bauen?
Beteiligen Sie sich am Gespräch auf dem Vonage Community Slack
Abonnieren Sie den Entwickler-Newsletter
Folgen Sie uns auf X (früher Twitter) für Updates
Sehen Sie sich die Tutorials auf unserem YouTube-Kanal
Verbinden Sie sich mit uns auf der Vonage Entwickler-Seite auf LinkedIn
Bleiben Sie auf dem Laufenden und halten Sie sich über die neuesten Nachrichten, Tipps und Veranstaltungen für Entwickler auf dem Laufenden.
Teilen Sie:
Aboze Brain John ist ein Technology Business Analyst bei Axa Mansard. Er hat Erfahrung in den Bereichen Datenwissenschaft und -analyse, Produktforschung und technisches Schreiben. Brain war an End-to-End-Datenanalyseprojekten beteiligt, die von der Datenerfassung, -exploration, -umwandlung und -verflechtung über die Modellierung bis hin zur Ableitung verwertbarer Geschäftserkenntnisse reichten, und er bietet Wissensführerschaft.