
Teilen Sie:
David is a Software Architect working on Vonage Call Centre, focussing on infrastructure, internal platform and frontend. He has experience across multiple industries including finance, IoT and Cloud Communications.
Selbstbedienungs-Datenspeicher
Lesedauer: 4 Minuten
Traditionell werden Datenspeicher von Spezialistenteams verwaltet und erfordern einen hohen Aufwand bei der Einrichtung und Verwaltung. Dieser Ansatz kann für monolithische Architekturen funktionieren. Für Microservices mit einer höheren Änderungsrate und dem Ziel, dass jeder seinen eigenen Datenspeicher hat, lässt sich dieses Modell jedoch nicht skalieren. Dies kann die Erstellung von Microservices teuer machen und die Teams werden von einem zentralen Team abhängig.
Das VCC (Vonage Kontaktzentrum) löste dieses Problem mit der Umstellung auf ein Selbstbedienung Modell umzusteigen, das auf Automatisierung setzt und es den Teams ermöglicht, viele dieser Aufgaben selbst auszuführen. Selbstbedienung ist jedoch ein recht abstraktes Konzept, so dass unsere erste Aufgabe darin bestand, zu definieren, was ein Selbstbedienungsdatenspeicher für uns bedeutet.
Ein Datenspeicher ist "ein Repository für die dauerhafte Speicherung und Verwaltung von Datensammlungen." Für uns umfasst dies:
Relationale Datenbank, z. B. MySQL
NoSQL-Datenbank, z. B. DynamoDB
Caches, z. B. Redis
Andere Geschäfte wie Elasticsearch
Selbstbedienung bedeutet, dass ein Team dies tun kann:
Erstellen und Verwalten ihres Datenspeichers
Schemaänderungen vornehmen
Sichere Datenänderungen vornehmen
Unterstützung ihres Datenspeichers, einschließlich Zugang für die Fehlersuche und Produktionsunterstützung
Diese Dinge sind an sich recht einfach zu tun. Um jedoch zu vermeiden, dass wir mehr Probleme schaffen, als wir lösen, müssen wir auch daran denken:
Werkzeuge, die bewährte Praktiken durch automatisierte Tests und Quality Gates
Audit-Protokoll für alle Zugriffe und Änderungen zur Gewährleistung der Konformität
Multi-Tenancy-Barrieren und -Fassaden (es ist nicht immer wirtschaftlich, einen Datenbank-Cluster pro Microservice zu haben)
Komplexität der Hot-Hot-Replikation, sofern erforderlich
Benutzerfreundlichkeit, Robustheit und Verbergen der internen Komplexität
Beide Hauptakteure von Datenspeichern (Teams, die Datenspeicher betreiben, und Funktionsteams, die Datenspeicher nutzen) profitieren vom Self-Service, allerdings auf unterschiedliche Weise. Je nach Ihrer Organisationsstruktur kann es sich sogar um dasselbe Team handeln! Die folgenden beiden Diagramme zeigen das Szenario der Einführung von Self-Service und der kontinuierlichen Verbesserung im Vergleich zum Nichtstun, über einen Zeitraum von 18 Monaten.
Diese Diagramme zeigen unsere Erfahrung, wie sich Business-as-Usual-Aufgaben wie die Durchführung von Schemamigrationen, Datenänderungen usw. auf die Teams auswirken, wenn die Nachfrage nach Datenspeichern im Laufe der Zeit steigt.
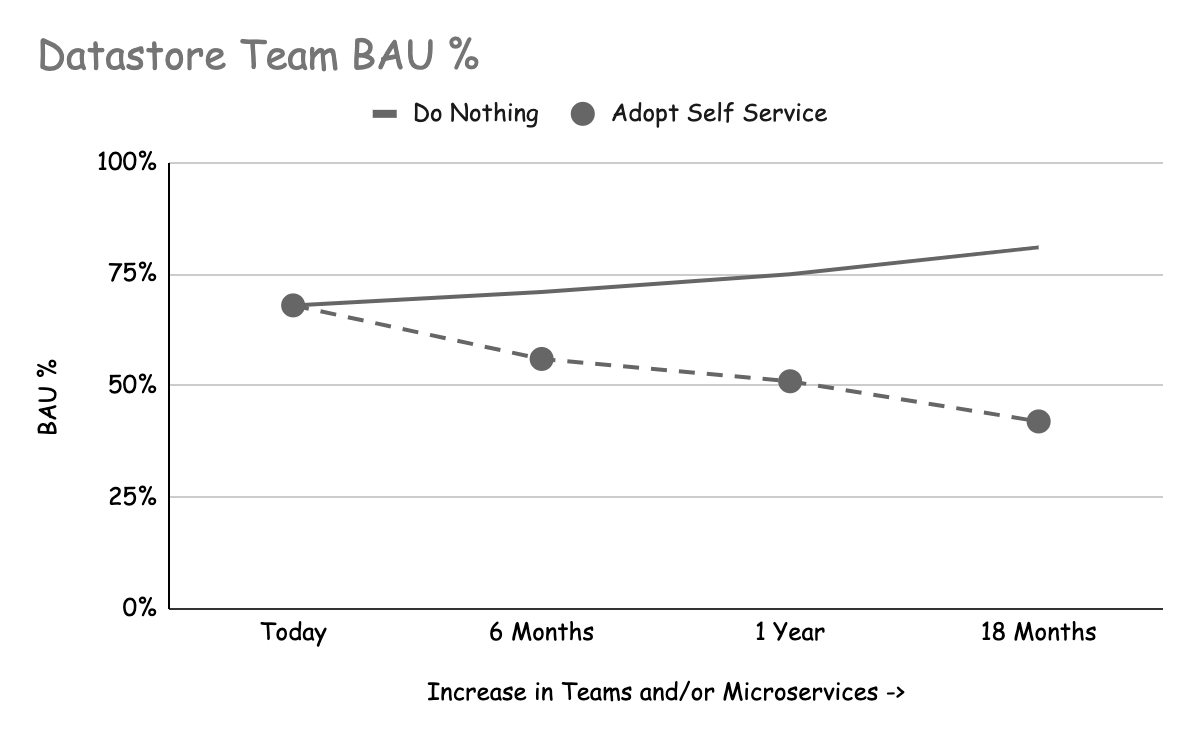 Impact from BAU tasks increases over time
Impact from BAU tasks increases over time
Wenn die Anzahl der Microservices und/oder Teams in Ihrem Unternehmen wächst, wird irgendwann der Punkt kommen, an dem die Menge an BAU Ihr(e) Datenspeicherteam(s) überfordert. Sie können dieses Problem durch die Einstellung von mehr Mitarbeitern lösen, aber es ist wahrscheinlich, dass dies nicht ausreicht, um mit der Nachfrage Schritt zu halten. Die Umstellung auf eine Self-Service-Strategie verringert die BAU, indem Aufgaben wie die Schemamigration wegfallen, während sich das Datastore-Team auf höherwertige Aufgaben konzentrieren kann.
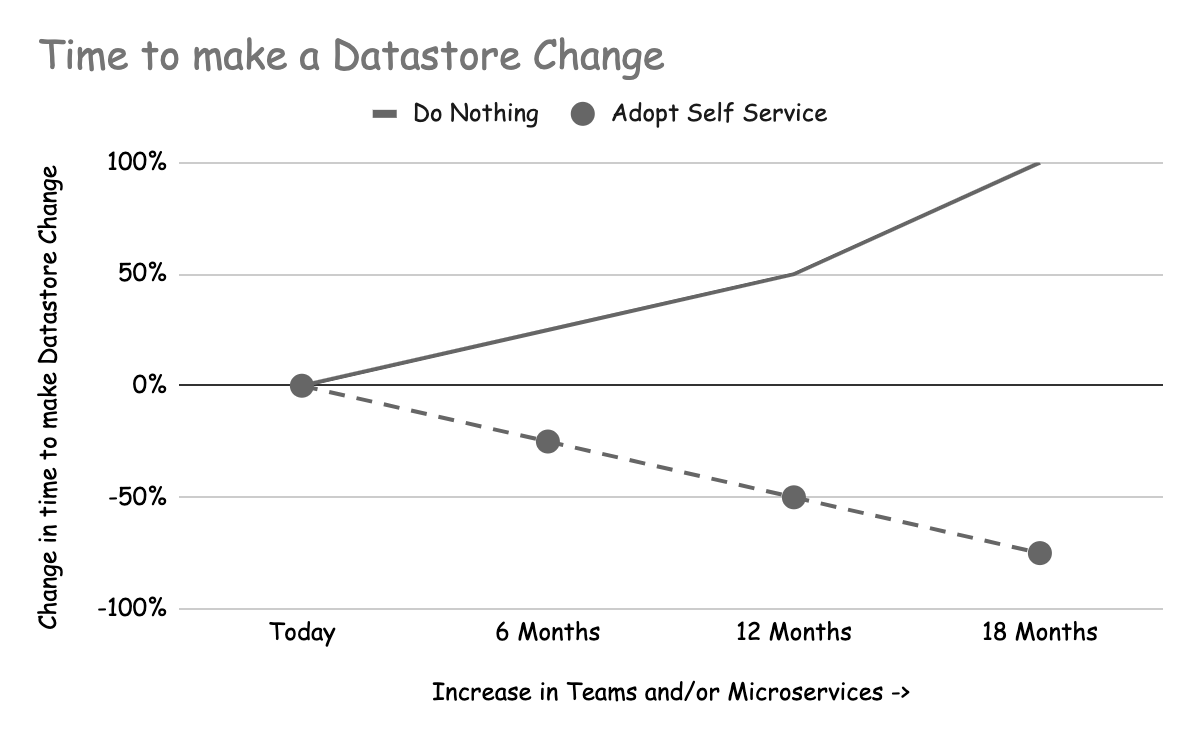 Time to make a datastore change increases over time
Time to make a datastore change increases over time
Auch Feature-Teams profitieren vom Self-Service, da Änderungen an Datenspeichern schneller und kostengünstiger durchgeführt werden können, je mehr Self-Service-Funktionen Sie hinzufügen. Wenn Feature-Teams von einem Datenspeicherteam abhängig sind, das diese Änderungen für sie vornimmt, kann dieses Team zu einem Engpass werden und die Kosten für Änderungen erhöhen. Diese Kosten machen sich vor allem in der verstrichenen Zeit bemerkbar. Wenn das Datenspeicherteam überfordert ist, müssen die Feature-Teams möglicherweise damit beginnen, die von ihnen angeforderten Änderungen zu verfolgen, um sicherzustellen, dass sie durchgeführt werden.
Jetzt, da Sie wissen, was ein Self-Service-Datenspeicher ist und warum wir ihn brauchen, sind Sie wahrscheinlich neugierig, was wir tun, um zu einem Self-Service-Modell überzugehen.
Teams, die an VCC arbeiten, haben die Selbstbedienung für AWS Aurora MySQLeingeführt, so dass wir automatisch neue Schemata für Services erstellen und Schemaänderungen als Teil der CI-Pipeline vornehmen können. Es kümmert sich auch um die Bereitstellung von Datenbankanmeldeinformationen und die Zugriffskonfiguration für Microservices.
Der Prozess für die Durchführung der Migrationen (wie im Diagramm unten dargestellt) umfasst ein Lambda, das die Erstellung von Docker-Containern zur Durchführung der Migrationen orchestriert. Die Kommunikation zwischen dem CI-System und dem Schemamigrationssystem erfolgt über Messaging. Der Prozess erstellt auch eine Datenbank, wenn das Schema noch nicht vorhanden ist.
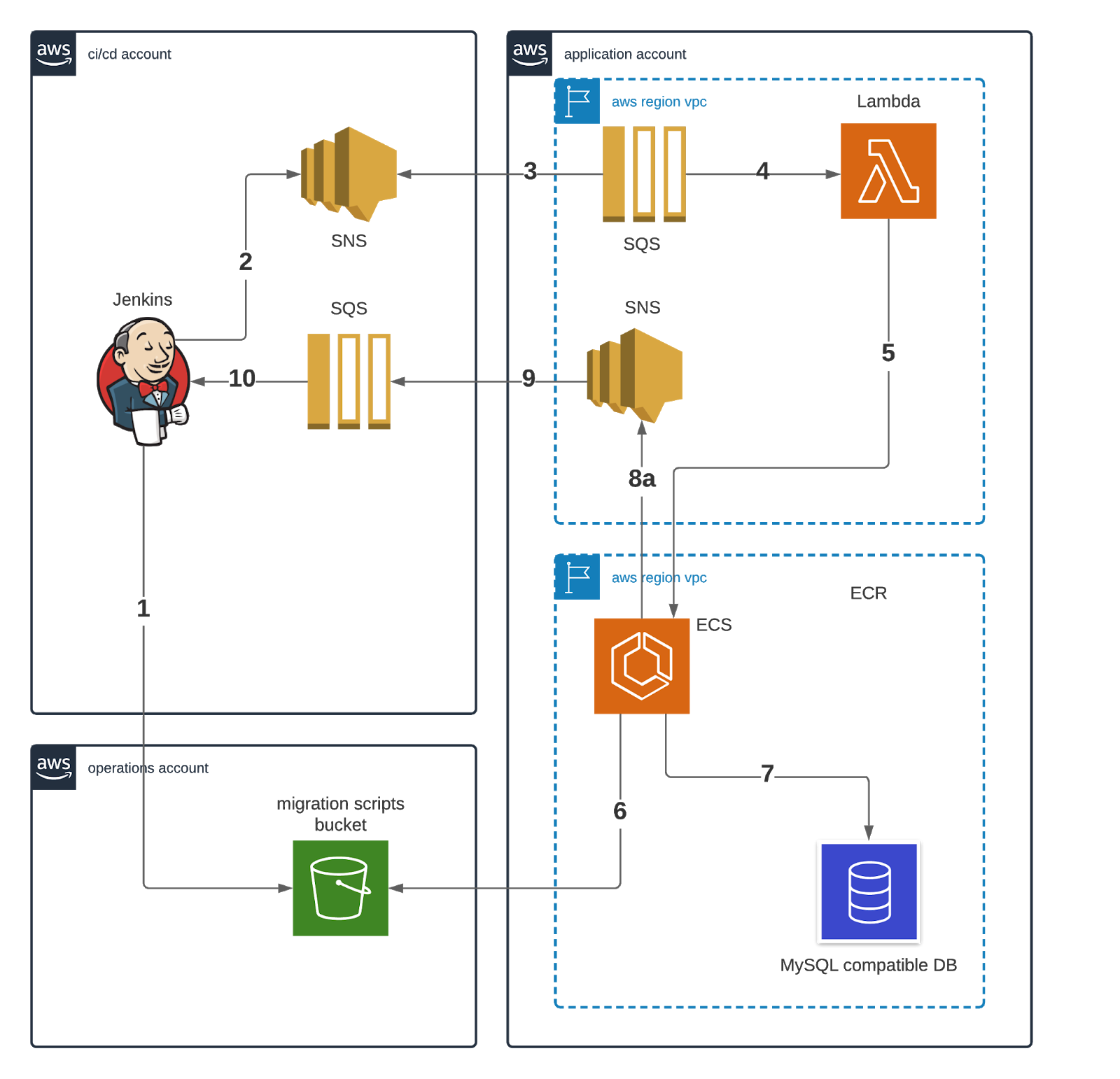
Der Arbeitsablauf des Migrationsprozesses besteht darin, dass Jenkins eine neue Version eines Schemas anfordert, die bereitgestellt werden soll, indem (1) die Migration in den Migrationsskript-Bucket hochgeladen und dann (2) in einem SNS-Thema veröffentlicht wird. Dies wird von (3) einer SQS aufgegriffen, die das Thema abonniert und (4) das Schemamigrations-Lambda anstößt.
Das Schemamigrations-Lambda (5) startet eine ECS-Aufgabe, deren (6) Container die Migration aus dem Migrationsskript-Bucket abruft und dann (7) ausführt flyway unter Verwendung des Migrationsskripts auf dem Ziel-Aurora-Cluster aus. Nach Abschluss der Migration (8) veröffentlicht der Container eine SNS-Nachricht, die (9) von einer CI/CD-SQS-Warteschlange abgeholt wird, die (10) den Status des Jenkins-Auftrags aktualisiert, um anzuzeigen, dass die Migration abgeschlossen ist.
Um dies zu unterstützen, haben wir außerdem Richtlinien für Best Practices erstellt, die speziell auf unsere Architektur zugeschnitten sind (z. B. Überlegungen zur Hot-Hot-Multicluster-Replikation und Best Practices für Migrationen, damit Teams häufige Fallstricke vermeiden können).
Als Nächstes wollen wir weitere Selbstbedienungsfunktionen hinzufügen, wie z. B. die Möglichkeit, Datenänderungen selbst vorzunehmen, mehr Kennzahlen bereitzustellen und Werkzeuge für eine detaillierte Abfrageanalyse zu entwickeln. Wir wollen einen sicheren, reibungsarmen Datenzugriff mit Integration in unseren Audit-Trail ermöglichen. Außerdem müssen wir überprüfen, ob die bereits geleistete Arbeit den erwarteten Nutzen gebracht hat.
Und schließlich prüfen wir, ob andere Teile von Vonage die von uns geleistete Arbeit nutzen können. Dies ist besonders wichtig, da wir die Vonage Kommunikationsplattform und die gemeinsame Architektur der internen Plattformen die sie untermauern sollen.