
Teilen Sie:
Steve ist ein ehemaliges Mitglied des Vonage-Teams. Er war .NET Developer Advocate bei Vonage, ein Full-Stack-Softwareentwickler mit Kenntnissen in mehreren Programmiersprachen sowie Spezialist für KI/ML.
Gesichtserkennung in Echtzeit in .NET mit OpenCV und Vonage Video API
Lesedauer: 12 Minuten
Hinweis: Einige der in diesem Artikel beschriebenen Tools oder Methoden werden möglicherweise nicht mehr unterstützt oder sind nicht mehr aktuell. Für aktualisierte Inhalte oder Support, überprüfen Sie unsere neuesten Beiträge oder unsere Dokumentation
Computer Vision ist mein Lieblingsgebiet in der Informatik. Es kombiniert meine vier Lieblingsfächer - Programmierung, lineare Algebra, Wahrscheinlichkeitsrechnung und Kalkül - zu etwas Praktischem und Leistungsfähigem. In diesem Artikel werden wir uns eine coole Anwendung von Computer Vision ansehen, die Gesichtserkennung, und diese Funktion in eine OpenTok Windows Presentation Framework(WPF)-App integrieren.
Um uns den Einstieg zu erleichtern, arbeiten wir mit der CustomVideoRender Beispiel von Vonage Video. Dieses Beispiel fügt dem Videobild einen blauen Farbton hinzu, wenn Sie den Filter einschalten. Wir werden diese blaue Schattierung entfernen und stattdessen eine Gesichtserkennung in den Renderer einbauen. Und ob Sie es glauben oder nicht, diese Gesichtserkennungsfunktion wird etwa 30 Mal schneller sein als der Blaufilter. Um dieses Kunststück zu vollbringen, werden wir den Viola-Jones Methode zur Erkennung von Merkmalen mit Emgu CV anwenden.
Wenn Sie keine Lust haben, dieses ganze Tutorial durchzuarbeiten, finden Sie ein funktionierendes Beispiel in GitHub. Stellen Sie nur sicher, dass Sie die Parameter wie in der Schnellstart-Anleitung aus dem Haupt-Repository für Beispiele
Ich werde nicht zu tief in die Funktionsweise der Viola-Jones-Methode eintauchen, aber für diejenigen, die es interessiert, hier ein paar kurze Hintergrundinformationen. Der Kern des Viola-Jones-Algorithmus ist dreifach. Erstens verwendet er so genannte Haar-ähnliche Merkmale, die wie alberne schwarze und weiße Formen aussehen könnten.
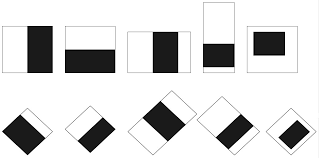 Haar-like feature shapes source: Source https://scc.ustc.edu.cn/
Haar-like feature shapes source: Source https://scc.ustc.edu.cn/
In Wirklichkeit sind sie jedoch Detektoren für sehr einfache Merkmale, die uns viel über die relative Schattierung eines Bildes verraten können:
 Harr-like Features over Faces source http://www.willberger.org/cascade-haar-explained/
Harr-like Features over Faces source http://www.willberger.org/cascade-haar-explained/
Bei der Überlagerung mit einem Bild wird die Summe des weißen Bereichs von der Summe des schwarzen Bereichs abgezogen, wodurch der Schattierungsunterschied zwischen den Regionen ermittelt wird. Diese Berechnungen können, wenn sie über viele Merkmale kaskadiert werden, eine gute Vorstellung davon vermitteln, wo in einem Bild sich ein Gesicht befinden könnte. Da diese Merkmale so einfach sind, sind sie skaleninvariant, d. h. sie können Gesichter in einem Bild finden, egal wie groß oder klein es ist.
Diese Methode leistet hervorragende Arbeit bei der Erkennung von Gesichtern in einem Bild, aber ohne die letzte wichtige Neuerung in dem Papier wäre diese Methode eher lähmend langsam als blitzschnell. Sie führten das Konzept eines integralen Bildes ein - ein integrales Bild ist ein Bild, bei dem jedes Pixel auf die Summe des Bereichs oberhalb und links des Pixels gesetzt wird. Indem wir dies für ein Eingabebild berechnen, können wir Berechnungen für Haar-ähnliche Merkmale mit einer Zeitkomplexität von O(1) statt O(N*M) durchführen, wobei N und M die Höhe bzw. Breite des Haar-ähnlichen Merkmals sind. Dadurch funktioniert die Kombinatorik nicht nur, sondern sie arbeitet auch zu unseren Gunsten, da wir versuchen, einen Gesichtsdetektor zu entwickeln, der schnell arbeitet.
Visual Studio - ich verwende 2019, aber ältere Versionen sollten funktionieren
Minimum .NET Framework 4.6.1 - Sie können auch 4.5.2 verwenden, aber Sie müssen EmguCV anstelle von Emgu.CV für Ihr OpenCV NuGet Paket verwenden.
CustomVideoRenderer-Beispiel - Dies ist das Beispiel, das wir anpassen werden.
Ein Vonage Video API Account - wenn Sie noch keinen haben melden Sie sich hier an.
Ein API-Schlüssel, eine Sitzungs-ID und ein Token von Ihrem Vonage Video API Account - siehe den Schnellstart Anleitung im Repo für Details.
Öffnen wir zunächst die CustomVideoRenderer-Lösungsdatei. Geben Sie in MainWindow.xaml.cs Ihre Anmeldeinformationen ein, falls Sie dies nicht bereits getan haben. Aktualisieren Sie dann das csproj, um das .NET Framework 4.6.1 zu verwenden.
Öffnen Sie dazu die Projektmappe in Visual Studio, klicken Sie mit der rechten Maustaste auf die Projektdatei und dann auf "Eigenschaften". Ändern Sie dann auf der Registerkarte "Anwendung" das Ziel-Framework auf 4.6.1.
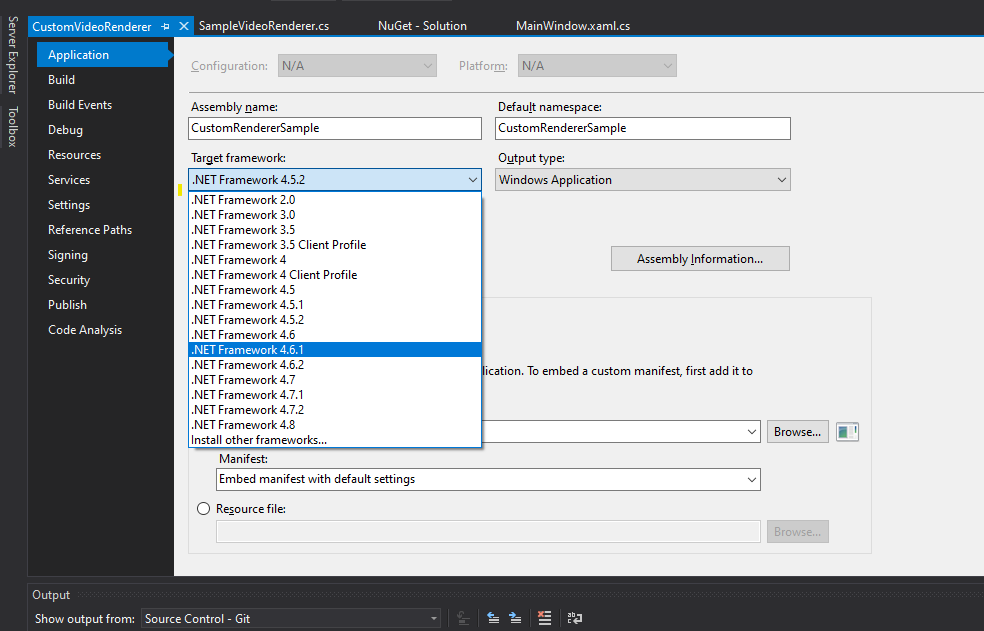 Upgrade .NET version
Upgrade .NET version
Als Nächstes fügen Sie die folgenden NuGet-Pakete zusätzlich zu den bereits in der Anwendung vorhandenen Paketen hinzu:
Emgu.CV.runtime.windows - Ich verwende 4.2.0.3662
WriteableBitmapEx - Ich verwende 1.6.5
Holen Sie sich die folgenden zwei Dateien von OpenCV:
haarcascade_frontalface_default.xml
haarcascade_profileface.xml
Legen Sie diese Dateien neben Ihr Projekt und stellen Sie sie so ein, dass sie in Ihr Build-Verzeichnis kopiert werden, wenn es gebaut wird. Dies kann die Einstellung einer Post-Build-Ereignis, wenn Ihr Visual Studio Instanz ist so unkooperativ wie meine:
copy $(ProjectDir)\haarcascade_profileface.xml $(ProjectDir)$(OutDir)
copy $(ProjectDir)\haarcascade_frontalface_default.xml $(ProjectDir)$(OutDir)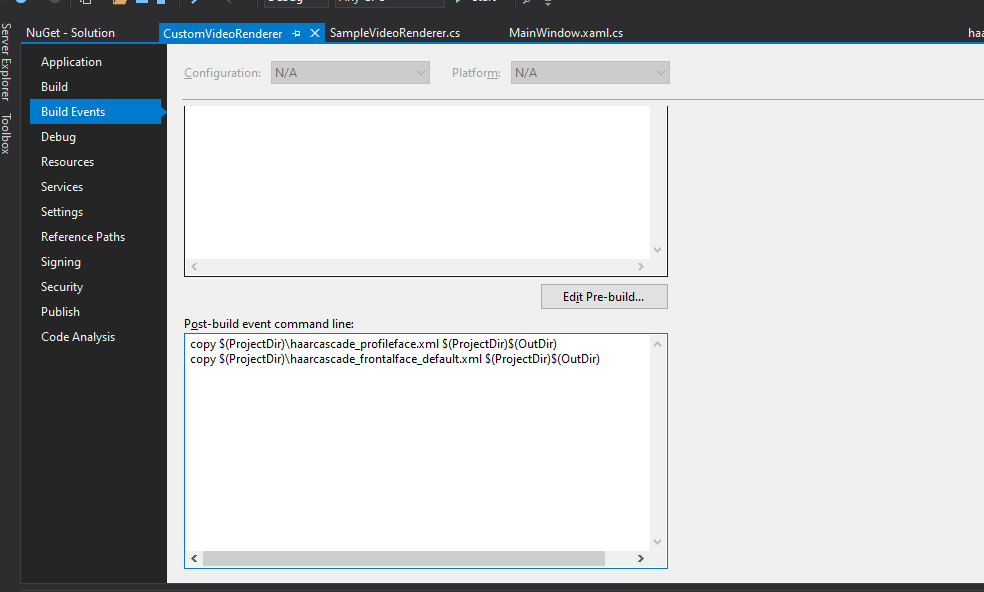 Displaying Post Build Events Screen
Displaying Post Build Events Screen
Jetzt sollten Sie die Anwendung starten und eine Verbindung zu einem Anruf herstellen können. Da Windows nicht zulässt, dass mehrere Anwendungen gleichzeitig auf die Kamera zugreifen können, müssen Sie sich möglicherweise von einem anderen Computer aus mit dem Vonage Video API Playground
 Running in Playground
Running in Playground
Wenn wir nun unseren Aufruf verbinden, sollte es in der Windows-App ungefähr so aussehen:
 Display Without Filter Windows App
Display Without Filter Windows App
Und wenn wir die Filter-Schaltfläche einschalten, sieht es eher so aus:
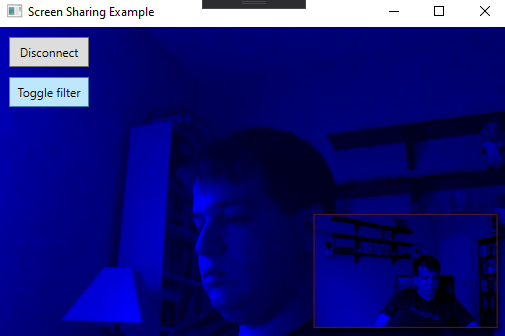 Display With Blue Filter Windows App
Display With Blue Filter Windows App
Bisher ist alles, was passiert, wenn Sie auf die Schaltfläche "Filter umschalten" klicken, wird die App einen blauen Farbton auf jedes Bild anwenden, das in den Renderer kommt.
Anstatt den standardmäßigen VideoRenderer zu verwenden, erstellen wir unseren eigenen benutzerdefinierten Renderer, SampleVideoRendererder Control erweitert und den IVideoRenderer der Vonage Video API implementiert. Diese Schnittstelle ist recht einfach: Sie hat eine Methode, RenderFramevon der wir den Frame übernehmen und auf eine Bitmap im Steuerelement zeichnen. So können wir jedes Mal, wenn ein Frame erscheint, eingreifen, das Gewünschte darauf anwenden und es rendern lassen.
Mit diesem benutzerdefinierten Renderer haben wir also alles, was wir brauchen, um mit dem Hinzufügen des CV zu unserer Anwendung zu beginnen. Öffnen wir SampleVideoRenderer.cs und fügen wir die folgenden Importe hinzu, bevor wir etwas anderes tun:
using Emgu.CV;
using Emgu.CV.Structure;
using System.Diagnostics;
using System.Drawing;
using System.Collections.Concurrent;
using System.IO;
using System.Threading;Wenn Sie schon hier sind, benennen Sie EnableBlueFilter in um. DetectingFaces (stellen Sie sicher, dass Sie die Umbenennungsfunktion Ihrer IDE verwenden) und machen Sie es zu einer öffentlichen get-, private set-Eigenschaft, anstatt zu einem öffentlichen Feld wie so:
public bool DetectingFaces { get; private set; }Das wird einige Dinge kaputt machen, aber es sollte bald klar werden, wie man sie beheben kann. Fürs Erste werden wir weitermachen.
Fügen Sie die folgenden Konstanten zu Ihrem Renderer hinzu:
private const double SCALE_FACTOR = 4;
private const int INTERVAL = 33;
private const double PIXEL_POINT_CONVERSION = (72.0 / 96.0);Die SCALE_FACTOR ist der Maßstab, auf den wir die Bilder für die Verarbeitung herunterskalieren - 4 bedeutet, dass wir die Bilder auf ein Viertel der Größe verkleinern, bevor wir die Erkennung durchführen. Die INTERVAL ist die Anzahl der Millisekunden zwischen den Bildern, die wir versuchen, aus dem Stream zu erfassen. 33 ist ungefähr die Anzahl der Millisekunden zwischen den Bildern in einem Stream mit 30 FPS, so dass der Parameter as-is bedeutet, dass er mit voller Geschwindigkeit läuft. Der Parameter PIXEL_POINT_CONVERSION ist das Verhältnis von Pixeln pro Punkt auf einem Bildschirm mit 96 DPI (was ich verwende). Natürlich kann dies besser berechnet werden, wenn wir das DPI-Bewusstsein berücksichtigen, aber wir werden dieses Verhältnis als Evangelium für jetzt verwenden. Wir brauchen dies nur, weil aus irgendeinem Grund die Bitmap Extensions-Bibliothek, die wir verwenden, scheint wie X in Punkte und Y in Pixel 🤷♂️ zu zeichnen.
Ich habe die Funktionsweise von Haar-ähnlichen Merkmalen bereits kurz erörtert, aber wenn Sie sich eingehender damit befassen möchten, lesen Sie bitte die Viola-Jones Arbeit. Das Tolle an OpenCV (und damit auch an EmguCV) ist, wie viel davon von uns abstrahiert wird.
Fahren Sie nun mit unserem SampleVideoRenderer fort. Gehen Sie nach unten und fügen Sie zwei statische CascadeClassifier als Felder hinzu:
static CascadeClassifier _faceClassifier;
static CascadeClassifier _profileClassifier;Im Konstruktor werden sie dann mit ihren jeweiligen Dateien initialisiert:
_faceClassifier = new CascadeClassifier(@"haarcascade_frontalface_default.xml");
_profileClassifier = new CascadeClassifier(@"haarcascade_profileface.xml");Diese XML-Dateien beschreiben die Haar's Features für den Klassifikator gut genug, um ihn zu trainieren. An diesem Punkt haben wir also den Klassifikator trainiert!
Während wir klassifizieren, wollen wir den Hauptthread nicht blockieren. Daher werden wir das Producer-Consumer-Muster implementieren. Wir werden Folgendes verwenden BlockingCollections. Insbesondere werden wir einen ConcurrentStack verwenden, da die wichtigsten und neuesten Frames ein und dasselbe sind. Fügen Sie die folgenden Felder zu unserer Klasse hinzu:
private System.Drawing.Rectangle[] _faces = new System.Drawing.Rectangle[0];
private BlockingCollection<Image<Bgr, byte>> _images = new BlockingCollection<Image<Bgr, byte>>(new ConcurrentStack<Image<Bgr, byte>>());
private CancellationTokenSource _source;
private Stopwatch _watch = Stopwatch.StartNew();Das Array _faces Array wird die Gesichter enthalten, die wir mit unserem Klassifikator erkannt haben, während die _images Sammlung, die mit einem ConcurrentStack initialisiert wird, die LIFO-Sammlung der zu verarbeitenden Bilder sein wird. Die CancellationTokenSource wird verwendet, um uns selbst aus der Verarbeitungsschleife herauszuziehen, wenn die Zeit gekommen ist. Die Stopwatch dient als Zeitmesser, der uns davor bewahrt, zu schnell Bilder zu erkennen.
Nun wollen wir unsere Verarbeitungsschleife implementieren. Fügen Sie die folgende Methode in Ihren Code ein:
private void DetectFaces(CancellationToken token)
{
System.Threading.ThreadPool.QueueUserWorkItem(delegate
{
try
{
while (true)
{
var image = _images.Take(token);
_faces = _faceClassifier.DetectMultiScale(image);
if(_faces.Length == 0)
{
_faces = _profileClassifier.DetectMultiScale(image);
}
if (_images.Count > 25)
{
_images = new BlockingCollection<Image<Bgr, byte>>(new ConcurrentStack<Image<Bgr, byte>>());
GC.Collect();
}
}
}
catch (OperationCanceledException)
{
//exit gracefully
}
}, null);
}In dieser Methode ist eine Menge los. Zunächst wird der Vorgang auf einem der verfügbaren Daemons des ThreadPools ausgeführt. Dann werden wir in einer engen Schleife verarbeiten. Wir rufen Take die blockierende Sammlung auf, um ein Bild vom Stapel zu ziehen. Dieser Take Aufruf wird blockiert, wenn sich nichts in der Sammlung befindet, und wenn wir den Abbruch signalisieren, wird eine OperationCanceledException ausgelöst, die wir weiter unten abfangen, um die Schleife elegant zu verlassen. Mit dem Bild wird die _faces Sammlung dem Ergebnis von DetectMultiScalezu, was die Methode zur Gesichtserkennung ist. Wenn dabei nichts gefunden wird, versuchen wir es erneut mit dem Profilgesichtsklassifikator.
Wenn all dies erledigt ist, überprüfen wir die Bildersammlung, um zu sehen, ob sie eine bestimmte Grenze überschritten hat (wir verwenden hier nur 25 als Beispiel). Wenn sie diese Grenze überschritten hat, weil der Klassifikator in Verzug geraten ist, löschen wir die Sammlung, indem wir sie neu instanziieren, und weisen dann den Garbage Collector an, die Bilder einzusammeln. Warum wird der Garbage Collector aufgerufen? Nun, das ist das Thema eines anderen Blogbeitrags, aber wenn Ihre Objekte zu groß sind (über 85.000 Byte), werden sie auf den Large Object Heap verschoben, dem der Garbage Collector eine niedrigere Priorität zuweist als anderen Objekten (da es ziemlich rechenintensiv ist, den Speicher freizugeben). In der Praxis bedeutet dies, dass Sie, wenn Sie relativ schnell mit großen Objekten zu tun haben, sicherstellen sollten, dass diese aufgeräumt werden, da Sie sonst einen hohen Speicherverbrauch haben werden.
Nun, wenn Sie meine Performance-Richtlinien unten folgen, werden Sie nie brauchen, um diesen Code zu treffen, aber ich lasse es in nur so, wenn die Leute sind Tuning sie nicht sehen, massive Spitzen in der Speichernutzung.
Fügen Sie nun den folgenden Code zu Ihrem Renderer hinzu:
public void ToggleFaceDetection(bool detectFaces)
{
DetectingFaces = detectFaces;
if (!detectFaces)
{
_source?.Cancel();
}
else
{
_source?.Dispose();
_source = new CancellationTokenSource();
var token = _source.Token;
DetectFaces(token);
}
}Dies wird das Umschalten des Gesichtsdetektors für Ihren Renderer zu verwalten. Wenn Sie es auf stop setzen, wird es der Token-Quelle sagen, dass sie abbrechen soll und Sie elegant aus der Schleife aussteigen. Wenn Sie sie auf start setzen, wird die alte CancellationTokenSource entsorgt, neu initialisiert, ein Token geholt und die Verarbeitungsschleife mit diesem Token gestartet.
Fügen wir noch einen Finalizer hinzu, um sicherzustellen, dass die Gesichtserkennungsaufgabe abgebrochen wird, wenn der Renderer beendet wird:
~SampleVideoRenderer()
{
_source?.Cancel();
}
Bis jetzt haben wir alle Grundlagen geschaffen, die wir für die Gesichtserkennung benötigen. Jetzt geht es nur noch darum, unseren Renderer dazu zu bringen, die Gesichtserkennung für jedes Bild durchzuführen. Gehen Sie nun in die RenderFrame Methode im SampleVideoRenderer. Löschen Sie die beiden verschachtelten for-Schleifen und ersetzen Sie diesen Code durch:
using (var image = new Image<Bgr, byte>(frame.Width, frame.Height, stride[0], buffer[0]))
{
if (_watch.ElapsedMilliseconds > INTERVAL)
{
var reduced = image.Resize(1.0 / SCALE_FACTOR, Emgu.CV.CvEnum.Inter.Linear);
_watch.Restart();
_images.Add(reduced);
}
}
DrawRectanglesOnBitmap(VideoBitmap,_faces);Dieser Filter zieht das Bild direkt aus dem Puffer, in den unser vorheriger Filter kopiert wurde, und schiebt das neue Bild auf unseren Blocking Stack, um dann die Rechtecke auf die erkannten Flächen zu zeichnen. Unterhalb der RenderFrame Methode fügen Sie die DrawRectanglesOnBitmap Methode hinzu, die wie folgt aussehen wird:
public static void DrawRectanglesOnBitmap(WriteableBitmap bitmap, Rectangle[] rectangles)
{
foreach (var rect in rectangles)
{
var x1 = (int)((rect.X * (int)SCALE_FACTOR) * PIXEL_POINT_CONVERSION);
var x2 = (int)(x1 + (((int)SCALE_FACTOR * rect.Width) * PIXEL_POINT_CONVERSION));
var y1 = rect.Y * (int)SCALE_FACTOR;
var y2 = y1 + ((int)SCALE_FACTOR * rect.Height);
bitmap.DrawLineAa(x1, y1, x2, y1, strokeThickness: 5, color: Colors.Blue);
bitmap.DrawLineAa(x1, y1, x1, y2, strokeThickness: 5, color: Colors.Blue);
bitmap.DrawLineAa(x1, y2, x2, y2, strokeThickness: 5, color: Colors.Blue);
bitmap.DrawLineAa(x2, y1, x2, y2, strokeThickness: 5, color: Colors.Blue);
}
}Dadurch wird das Rechteck als 4 separate Linien auf die Bitmap gezeichnet und angezeigt - beachten Sie, dass wir die PIXEL_POINT_CONVERSION nur für das x verwenden.
Mir ist aufgefallen, dass das PublisherVideo-Element im MainWindow etwas klein ist, so dass ich nicht erkennen kann, was darin vor sich geht. Zu Testzwecken habe ich also die Größe des Fensters verdoppelt oder vervierfacht. Passen Sie dazu einfach die Höhe und Breite in Zeile 12 von MainWindow.xaml an.
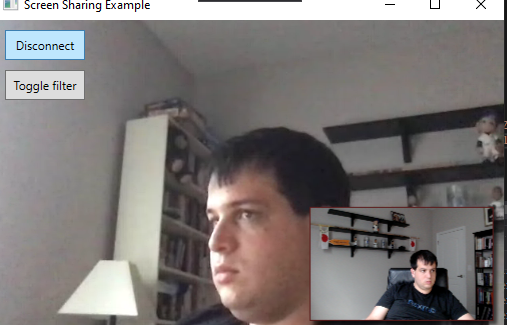
Jetzt sind wir bereit - starten Sie die App und drücken Sie die Toggle Filter in der oberen linken Ecke des Bildschirms. Dadurch wird der Filter aktiviert. Sie sollten ihn in der Vorschau sehen, und wenn Sie eine Verbindung zu einem Anruf herstellen, können Sie sehen, dass die Gesichtserkennung auch bei den anderen Teilnehmern funktioniert.
 Display Example With Face Detection
Display Example With Face Detection
Sie werden sehen, dass diese Art der Merkmalserkennung sowohl genau als auch schnell ist. Der Filter läuft in etwa 10 ms, im Vergleich zu den ~30 ms für den geänderten blauen Filter. Und da die Hauptverarbeitung auf einem Worker-Thread läuft und das eigentliche Zeichnen weniger als eine Millisekunde dauert, ist dies tatsächlich etwa dreißig Mal schneller, was bedeutet, dass das Hinzufügen von Gesichtserkennung aus einer UX-Perspektive praktisch kostenlos ist.
Keine Diskussion über Computer Vision wäre vollständig ohne einen kleinen Hinweis auf die parametrische Abstimmung. Es gibt alle Arten von Parametern, die Sie hier potenziell einstellen können, aber ich werde mich nur auf zwei konzentrieren:
Intervall zwischen den Bildern
Skalierungsfaktor
Wie bereits erwähnt, funktionierten die 33 Millisekunden zwischen den Einzelbildern für mich, vor allem wenn ich den Skalierungsfaktor entsprechend einstellte. Der Skalierungsfaktor war der wichtigste Faktor für die Leistung. Wenn Sie den Skalierungsfaktor auf 1 setzen - mit anderen Worten, versuchen Sie, ein ganzes Bild (in meinem Fall 1280x720) aufzunehmen -, dann sind das 921.000 Pixel, die alle 33 Millisekunden verarbeitet werden müssen, was einen erheblichen Leistungsverlust zur Folge hat. Auf meinem Rechner würde dies mit etwa 200 ms pro Bild ablaufen, meine CPU auslasten und ohne den expliziten Aufruf des Garbage Collectors den Speicherverbrauch explodieren lassen. Denken Sie daran, dass der Skalierungsfaktor quadratisch ist. Wenn Sie also den Skalierungsfaktor auf 4 setzen, verringert sich die Anzahl der Pixel um den Faktor 16. Bei meinen Tests konnte ich keine Beeinträchtigung der Genauigkeit bei der Größenänderung feststellen.
Wir belassen es vorerst dabei, aber ich hoffe, dass dieser Beitrag den Leser inspiriert, das immense Potenzial von OpenCV in .NET zu erkennen. Einige nette Applications, für die man das nutzen könnte, fallen mir spontan ein:
Hinzufügen von Filtern und Integrieren von AR in Ihre Apps. Sehen Sie sich einige Artikel über Homographien und Feature-Tracking-Algorithmen. Ich persönlich mag ORB (schon allein deshalb, weil er viel freier ist als andere Feature-Tracking-Algorithmen).
Sie könnten Far End Camera Control (FECC) in Ihre App integrieren und die Kamerabewegungen so einstellen, dass sie Ihr Gesicht verfolgen!
Sobald Sie den Gesichts-ROI in Ihrem Bild gefunden haben, können Sie viel effizienter Dinge durchführen wie Stimmungsanalyse.
Wie man sich denken kann, ist dies der erste Schritt der Gesichtserkennung.
Sie können ein funktionierendes Beispiel aus diesem Tutorial in GitHub finden hier
Alles, was Sie über Vonage Video API wissen möchten, finden Sie auf unserer Website
Alles, was Sie jemals über OpenCV wissen wollen, finden Sie in deren docs
Überprüfen Sie Emgu's wiki Seite um mehr über die Verwendung von Emgu im Speziellen zu erfahren. Wenn Sie wie ich ein OpenCv-Python-Fan sind, werden Sie kein Problem haben, Emgu zu benutzen