
Teilen Sie:
Yotam ist ein Principal Data Scientist bei Vonage. Er bringt seinen Doktortitel in Computational Neuroscience und seine Leidenschaft für ethische Datenwissenschaft in jedes Projekt ein, das er in Angriff nimmt. In der Vergangenheit leitete er ein durch Fördermittel finanziertes Forschungsprojekt zur Entwicklung eines mimikgesteuerten Kommunikationstools für ALS-Patienten, das auf einer kostengünstigen, leicht zugänglichen Stirn-Elektroden-Technologie basiert.
Mann in der Schleife vs. LLM in der Schleife
Lesedauer: 7 Minuten
Bei der KI ist die Balance zwischen menschlicher Kontrolle ("man in the loop") und Automatisierung ("LLM in the loop") entscheidend für den Aufbau von Lösungen für die Praxis. Wir bei Vonage AI, dem Team, das für die Entwicklung von KI-Diensten innerhalb von Vonage verantwortlich ist, sahen uns dieser Herausforderung gegenüber, als wir unsere Speech-to-Text (STT)-Systeme neu gestalteten, um den wachsenden Anforderungen an die genaue Transkription in Callcentern gerecht zu werden.
Um die Grenzen des traditionellen Benchmarking zu überwinden, haben wir einen neuen Ansatz entwickelt, bei dem große Sprachmodelle (Large Language Models, LLMs) eingesetzt werden, um durch die Verarbeitung der Ergebnisse mehrerer STT-Anbieter qualitativ hochwertige Referenztranskriptionen zu erzeugen. Anstatt sich auf von Menschen erstellte Referenzen oder eine einzelne "Grundwahrheit" zu verlassen, synthetisiert das LLM eine Konsenstranskription, indem es sein Verständnis von Sprache und Kontext über alle Eingaben hinweg nutzt.
Diese von LLM abgeleitete Referenz ermöglicht eine skalierbare, unverzerrte und kontextabhängige Berechnung der Wortfehlerrate (WER) für jeden Anbieter.
In diesem Beitrag erfahren Sie, wie diese LLM-basierte Methode im Vergleich zum traditionellen Benchmarking abschneidet, wobei der Schwerpunkt auf den folgenden Punkten liegt:
Die Grenzen der derzeitigen Benchmarking-Methoden
Wie LLMs Referenztranskriptionen synthetisieren
Die wichtigsten Erkenntnisse aus unseren Experimenten
Wir bei Vonage AI sind ein Team von Forschern und Ingenieuren, die sich der Aufgabe verschrieben haben, die Grenzen des Möglichen mit künstlicher Intelligenz zu erweitern. Im Rahmen des Engagements von Vonage für intelligente Kommunikation konzentrieren wir uns sowohl auf innovative Konversations-KI als auch auf die Kernforschung im Bereich des maschinellen Lernens, um robuste, skalierbare und zukunftsweisende KI-Lösungen zu entwickeln. In diesem Beitrag erfahren Sie mehr über eine unserer Forschungsbemühungen: Wir überdenken die Art und Weise, wie wir die Transkriptionsgenauigkeit in einer sich schnell verändernden Welt mit mehreren Modellen bewerten.
Vor einigen Jahren, als wir unsere STT-Modelle für die verschiedenen Dialekte in den Call Centern unserer Kunden feinabgestimmt haben Kunden-Call-Center stützten wir uns bei der Transkription von Audioschnipseln stark auf menschliche Kommentatoren. Diese Transkriptionen dienten als "Ground Truth" für das Training und die Evaluierung unserer internen Modelle.
Dieser Prozess ist zeitaufwändig und verlangsamt die Entwicklungszyklen.
Die hohen Kosten erschweren eine effektive Skalierung.
Menschliche Prüfer beginnen oft mit bereits vorhandenen Transkriptionen, was zu einer Verzerrung ihrer Korrekturen führen kann.
Die Aufgabe ist geistig anspruchsvoll und erhöht mit der Zeit die Wahrscheinlichkeit menschlicher Fehler.
Die Herausforderungen haben sich jedoch gelohnt: Unser fein abgestimmtes proprietäres Modell übertraf schließlich die Lösungen führender Drittanbieter für unseren speziellen Anwendungsfall.
Da sich die Kundenbedürfnisse weiterentwickelten, standen wir vor neuen Herausforderungen bei der manuellen Etikettierung
Die Unterstützung neuer Sprachen und Dialekte erforderte die Einstellung von Fachleuten, die die jeweilige Sprache fließend beherrschen.
Für das Testen von branchenspezifischen Anwendungsfällen, wie z. B. der medizinischen Transkription, waren Menschen mit Fachwissen erforderlich.
Das schnelle Wachstum fortschrittlicher Open-Source-Modelle führte zu mehr Optionen für die Bewertung, den Einsatz und die Feinabstimmung; daher benötigten wir eine skalierbare und konsistente Methode zur Bewertung der Genauigkeit, ohne wochenlang auf die manuelle Transkription warten zu müssen.
Infolgedessen begann eine neue Ära: LLM in der Schleife.
Anstatt sich bei der Transkription von Audiodaten auf Menschen zu verlassen, verwenden wir jetzt ein Large Language Model (LLM), um Referenztranskriptionen zu erstellen. Das LLM analysiert die Ergebnisse verschiedener Transkriptionssysteme und gleicht sie miteinander ab, um die genaueste Rekonstruktion des Gesagten zu erzielen. Manchmal gleicht es die Ergebnisse eines Modells für ein Teilsegment des Audios mit denen eines anderen Modells für einen anderen Teil des Audios ab.
Es ist, als hätte man einen klugen, schnellen Schiedsrichter, der:
Liest mehrere Transkriptionen desselben Tons
Versteht Kontext und sprachliche Nuancen
Erzeugt eine zuverlässige, unvoreingenommene "Referenz", mit der Modelle verglichen werden können
Zur Validierung des Konzepts haben wir ein bekanntes Korpus verarbeitet, das wir zuvor manuell beschriftet hatten. Wir nutzten es, um die Genauigkeit der LLM-gesteuerten Pipeline abzuschätzen und gleichzeitig den ursprünglichen Beitrag der manuellen Beschriftung zu bewerten.
Das haben wir entworfen:
Wir transkribierten dieselben 5-15 Sekunden langen Audioschnipsel mit mehreren STT-Systemen, darunter unsere eigenen Modelle, Open-Source-Modelle und Drittanbieter.
Für jeden Clip sammelten wir alle Transkriptionen zusammen mit den ursprünglichen menschlichen Bezeichnungen. Dann haben wir dem LLM diese Alternativen (ohne Kenntnis der Quellen) vorgelegt und ihn gebeten, die genaueste, wahrscheinlichste Transkription für diesen Ausschnitt zu erstellen.
Unter Verwendung dieser vom LLM generierten "synthetischen Grundwahrheit" für ~300 Proben haben wir die Wortfehlerrate (WER) für jedes STT-System berechnet.
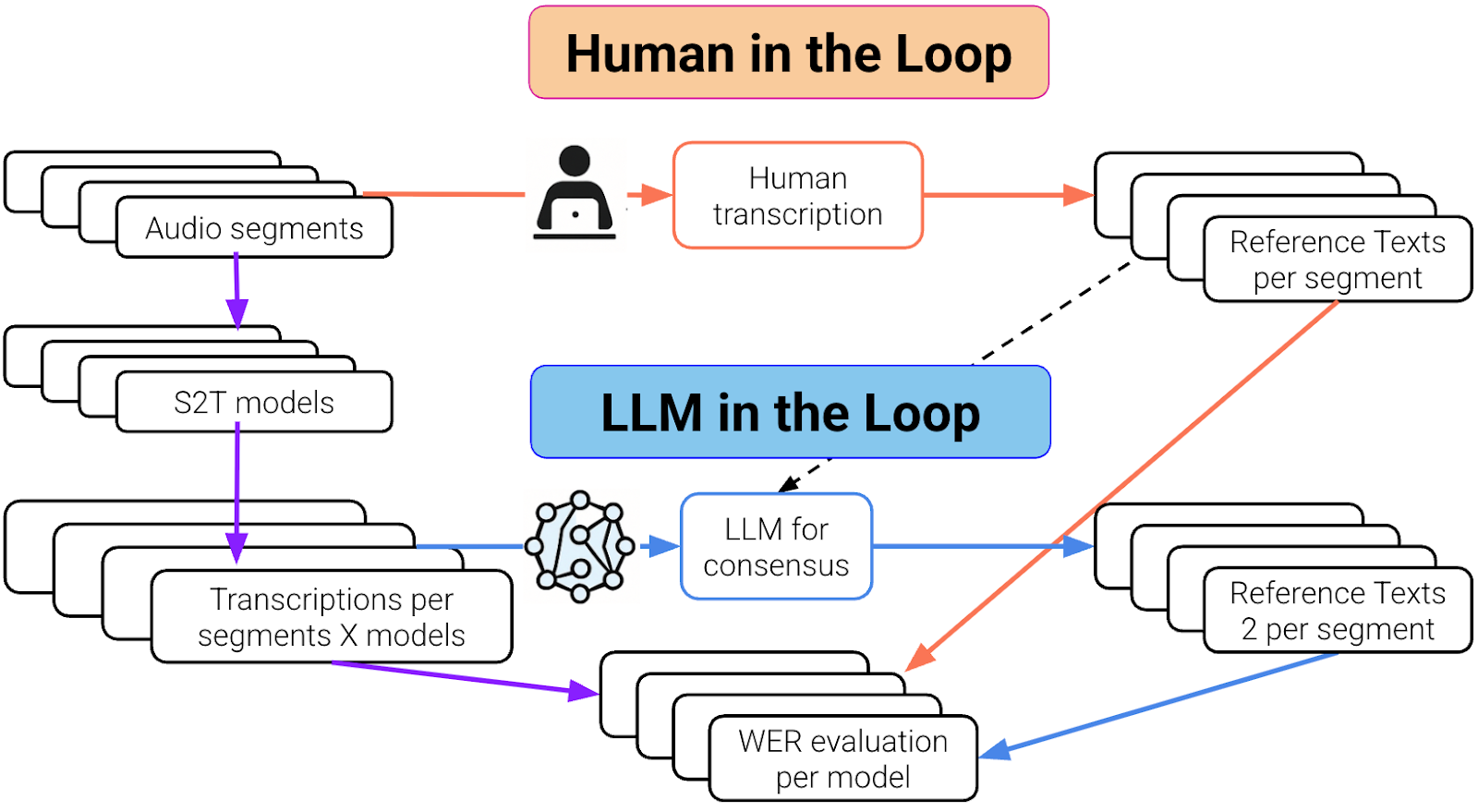 Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Workflow comparison of human-in-the-loop and LLM-in-the-loop methods for generating reference transcriptions and evaluating speech-to-text model accuracy.
Die menschliche und die LLM-Schleife. Der violette Teil ist bei beiden Schleifen gleich.
Stellen Sie sich vor, Sie haben die folgenden STT-Ausgaben von verschiedenen Anbietern für ein kurzes Agenten-Audio-Snippet:
 Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Example of transcription variations from multiple speech-to-text models for the same audio snippet, used by the LLM to synthesize a consensus reference.
Diese Transkriptionen unterscheiden sich in der Formatierung, der numerischen Darstellung und der Genauigkeit und spiegeln die typischen Ergebnisse der verschiedenen Modelle wider.
Der LLM wird angewiesen, zwei aufeinander abgestimmte Referenztranskriptionen zu erzeugen:
Alphabetische Referenz:
Wenn die Frist von vierundzwanzig Stunden verstreicht, wird eine Gebühr von fünfzig Dollar fällig, wenn die Stornierung bis zu acht Tage vor der Ankunft erfolgt.
Alphanumerische Referenz:
Wenn die 24-Stunden-Frist verstreicht, wird eine Stornogebühr von 50 Dollar fällig, die bis zu 8 Tage vor der Ankunft zu entrichten ist.
Dieser Ansatz gewährleistet einen fairen (und formatierungsneutralen) Vergleich zwischen verschiedenen Arten von Modellergebnissen: Nicht-formatierende Modelle (wie unsere Lösung) werden an nicht-formatierten Referenzen gemessen, während formatierungsfähige Modelle an formatierten Referenzen gemessen werden, die die gleiche Bedeutung haben.
Die folgenden Modelle wurden getestet:
Vonage AI (VAI) - Unser hausinternes, fein abgestimmtes Modell, das vom gleichen Team auf manuell gekennzeichneten Daten trainiert wurde
Vonage AI (VAI) - Unser älteres Modell, das nicht auf diesen Anwendungsfall abgestimmt ist
Die Original-Transkriptionen mit menschlicher Beschriftung
Drei Open-Source-Modelle von OpenAI: Whisper-Large(V3), Whisper-Medium, Whisper-Small
Zwei Drittanbieter
Um die Rolle der menschlichen Referenzen zu untersuchen, haben wir die LLM-basierte Bewertungspipeline in zwei Konfigurationen verwendet:
Label-In: Die menschliche Transkription wurde in die alternativen Ausgaben aufgenommen, die dem LLM zur Referenzsynthese vorgelegt wurden.
Kennzeichnung aus: Die menschliche Transkription wurde von den Alternativen, die dem LLM gezeigt wurden, ausgeschlossen (verblindet).
Wir haben die beiden verglichen, um die Robustheit der LLM-generierten Referenz und mögliche Verzerrungen durch vom Menschen markierte Daten zu bewerten.
Wir haben die Wortfehlerrate (WER) als Hauptbewertungsmaßstab verwendet. Dies ist ein Standardmaß für die Transkriptionsqualität. WER quantifiziert die Anzahl der Fehler in einer Transkription, indem sie mit einer Referenz verglichen wird. Diese Fehler fallen in drei Kategorien:
Einfügungen: zusätzliche Wörter hinzugefügt
Streichungen: Wörter, die übersehen wurden
Substitutionen: falsche Wörter anstelle der richtigen
WER wird nach der folgenden Formel berechnet:
 Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Formula for calculating Word Error Rate (WER) in speech-to-text benchmarking: the sum of insertions, deletions, and substitutions divided by the total words in the reference, multiplied by 100.
Ein niedrigerer WER bedeutet eine genauere Transkription.
 Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Comparison of Word Error Rate (WER) across speech-to-text models, showing results with human-labeled references (blue) versus LLM-generated references (red).
Die WERs waren in beiden Setups nahezu identisch, was die Robustheit der LLM-generierten Referenzen beweist.
Stabile Ranking- und WER-Werte für die meisten Modelle sowohl bei Label-In- als auch Label-Out-Einstellungen.
"3rd-Party 2" zeigte eine bemerkenswerte Verbesserung, wenn das menschliche Label ausgeschlossen wurde (WER 10.5 → 9.5), was auf eine bessere Übereinstimmung mit LLM-generierten Ergebnissen als mit menschlichen Annotationen hindeutet.
Menschlich beschriftete Transkriptionen wiesen bei dieser Auswertung einen höheren WER auf als fast alle automatischen Modelle. Dies war zu erwarten, da das Korpus von englischen Nicht-Muttersprachlern transkribiert wurde und das Annotationstool keine Schutzmechanismen für Tippfehler enthielt.
Das VAI-Feinabstimmungsmodell, das vom gleichen Team anhand menschlicher Beschriftungen trainiert wurde, übertraf noch immer sein unabgestimmtes Gegenstück (WER 13,7 → 12,5), was den Nutzen solcher Daten trotz ihrer Unzulänglichkeiten zeigt.
Diese Ergebnisse zeigen, dass LLM-generierte Referenztranskriptionen zuverlässig, konsistent und skalierbar für das Benchmarking von STT-Systemen sind. Die nahezu identischen WERs und Rankings über alle Evaluierungen hinweg, mit und ohne menschlich beschriftete Daten, unterstreichen die Robustheit der Pipeline.
Auch wenn einige Modelle besser mit der Tokenisierung oder dem Formatierungsstil des LLM übereinstimmen (wie bei "3rd-Party 2"), bieten die aus dem LLM abgeleiteten Referenzen insgesamt eine faire und reproduzierbare Bewertungsmethode.
Wichtig ist, dass die von Menschen beschrifteten Referenzen zwar höhere Fehlerquoten aufwiesen, aber dennoch für die Modellschulung wertvoll sind. Die Feinabstimmung mit solchen Daten verbesserte die Modellleistung erheblich, was die Bedeutung von beschrifteten Daten bei der Modellentwicklung bekräftigt, selbst wenn die Auswertung automatisiert werden kann.
LLMs können zuverlässige Referenztranskriptionen erzeugen, die ein skalierbares Benchmarking mit hohem Durchsatz ermöglichen.
Mit Menschen gekennzeichnete Referenzen sind für die Bewertung nicht mehr erforderlich, bieten aber weiterhin Vorteile für die Ausbildung.
Diese Methode beschleunigt das faire Benchmarking über neue Modelle, Sprachen und Bereiche hinweg und macht die manuelle Transkription überflüssig.
Möchten Sie Ihren eigenen KI-Agenten erstellen und verschiedene Lösungen vergleichen? Sie können Ihren eigenen AI Studio-Agent ausprobieren und ihn mit verschiedenen Lösungen von Drittanbietern wie Deepgram kombinieren und herausfinden, welche für Sie am besten funktioniert.
Haben Sie eine Frage oder möchten Sie uns mitteilen, was Sie gerade bauen?
Beteiligen Sie sich am Gespräch auf dem Vonage Community Slack
Abonnieren Sie den Entwickler-Newsletter
Folgen Sie uns auf X (früher Twitter) für Updates
Sehen Sie sich die Tutorials auf unserem YouTube-Kanal
Verbinden Sie sich mit uns auf der Vonage Entwickler-Seite auf LinkedIn
Bleiben Sie auf dem Laufenden und halten Sie sich über die neuesten Nachrichten, Tipps und Veranstaltungen für Entwickler auf dem Laufenden.
Teilen Sie:
Yotam ist ein Principal Data Scientist bei Vonage. Er bringt seinen Doktortitel in Computational Neuroscience und seine Leidenschaft für ethische Datenwissenschaft in jedes Projekt ein, das er in Angriff nimmt. In der Vergangenheit leitete er ein durch Fördermittel finanziertes Forschungsprojekt zur Entwicklung eines mimikgesteuerten Kommunikationstools für ALS-Patienten, das auf einer kostengünstigen, leicht zugänglichen Stirn-Elektroden-Technologie basiert.