
Teilen Sie:
IOS-Entwickler, der sich für Data Science und maschinelles Lernen begeistert. Ich möchte, dass die Menschen verstehen, was maschinelles Lernen ist und wie wir es in unseren Applications nutzen können.
Einführung in GPT-3
Lesedauer: 8 Minuten
Falls Sie es noch nicht bemerkt haben: KI ist allgegenwärtig, und wir sind endlich an einem Punkt angelangt, an dem sie in fast allen Bereichen, mit denen wir interagieren, zum Einsatz kommt. Von Amazon-Produktempfehlungen über Netflix-Vorschläge bis hin zum autonomen Fahren und dem Schreiben hervorragender Blogbeiträge... Keine Sorge, dieser Beitrag wurde von einem Menschen geschrieben - vorerst.
Viele Menschen sehen, wie KI eingesetzt wird, aber haben Sie sich jemals gefragt, wie sie zustande kommt?
Dieser Beitrag befasst sich mit einem sehr beliebten Modell, das für viele Aufgaben verwendet wird, z. B. für die Erstellung von Nachrichtenartikeln, die Erzeugung von Bildern und sogar für die Erstellung von HTML-Seiten.
Zunächst eine grundlegende Zusammenfassung von KI: Es handelt sich um eine Reihe von Algorithmen, die eine bestimmte Aufgabe erlernen und Vorhersagen zu ähnlichen Aufgaben treffen können. Eine dieser Aufgaben könnte vorhersagen, ob ein Bild das Bild einer Katze oder eines Hundes enthält.
In diesem Beispiel sammeln wir viele dieser Bilder und geben sie in einen Algorithmus ein. Dann beschriften wir jedes Bild, wie z. B. "Dies ist ein Foto von einem Hund" oder "Dies ist ein Katzenfoto". Der Algorithmus "lernt", welche Bilder einen Hund oder eine Katze enthalten. Das Modell macht Annahmen darüber, was einen Hund (große Ohren, flauschiger Schwanz) und eine Katze (Schnurrhaare, Augenform) ausmacht und kann diese Unterschiede lernen.
Wir geben unserem Modell Hunderte von Bildern, die wir als "Training" bezeichnen, damit es sich eine gute Vorstellung davon machen kann, wie ein Hund und eine Katze aussehen. Schließlich geben wir dem Modell ein neues Bild, und es sollte in der Lage sein, uns zu sagen, ob es sich um ein Bild von einem Hund oder einer Katze handelt.
Wenn Sie lernen möchten, wie man ein Modell zur Identifizierung von Hunden baut, sehen Sie sich bitte dies an (https://developer.vonage.com/en/blog/dog-breed-detector-using-machine-learning-dr).
Die Idee, ein Modell mit Beispielen (Bilder von Katzen und Hunden) zu trainieren und Vorhersagen für neue Bilder zu treffen, ist Deep Learningdas eine Teilmenge der KI ist.
Wir werden in diesem Beitrag nicht darauf eingehen, wie man ein Modell trainiert, aber wir werden ein sehr beliebtes Modell vorstellen, das weitere interessante Dinge tun kann.
Im Juni 2020 veröffentlichte ein Unternehmen namens OpenAI (gegründet von Elon Musk) ein neues Modell namens GPT-3das in der Lage ist, aus einer kleinen Anzahl von Eingabedaten neue Inhalte zu generieren.
Beispiele dafür, wie Sie dies nutzen können, sind:
Fragen und Antworten
Zusammenfassende Sätze
Übersetzung
Textgenerierung
Bilderzeugung
Ausführen von dreistelligen Arithmetikaufgaben
Wörter entschlüsseln
GPT-3 ist ein Deep-Learning-Sprachmodell, d. h., dieses Modell wurde auf Tausenden von Artikeln aus Wikipedia, Websites und Büchern trainiert.
Wenn ein Modell trainiert wird, besteht seine Ausgabe aus einer Reihe von Parametern, in der Regel einer mehrdimensionalen Reihe von Numbers. Diese Numbers geben an, was das Modell gelernt hat.
GPT-3 enthält 175 Milliarden Parameter. Zur Veranschaulichung: Microsoft hat auch ein Sprachmodell herausgebracht, das nur 10 Milliarden Parameter verwendet.
Damit ein Modell aus den gegebenen Daten lernen kann, muss es trainiert werden. Dieses Training erfolgt, indem man dem Modell jedes Wort eines gegebenen Textes vorgibt und dann das nächste Wort vorhersagt.
Dieses Training ist rechenintensiv und erfordert viele GPUs zum Trainieren. Einer Schätzung zufolge kostet das Training des GPT-3-Modells 4,6 Millionen Dollar.
GPT-3 ist als (G)enerativer (P)re-trained (T)ransformer bekannt. Generativ bedeutet, dass er bei einer Texteingabe neuen Text erzeugen kann.
Wenn wir dem Modell zum Beispiel den folgenden Text geben:
"Der Himmel ist"
Das Modell sollte in der Lage sein, vorherzusagen, dass das nächste Wort "blau" ist.
Wenn ich einen weiteren Satz gebe:
"Der schlaue braune Fuchs"
Das Modell würde zunächst "sprang" vorhersagen, dann anhand des vorherigen Satzes ("Der schlaue braune Fuchs sprang") das Wort "über" vorhersagen und so weiter.
Ein weiterer Bestandteil des GPT-3 ist der Transformator. Der Transformator ist eine von Google entwickelte Architektur, die es einem Modell ermöglicht, sich an eine Phrase oder eine Gruppe von Phrasen in einem gegebenen Satz zu erinnern oder diese höher zu gewichten, wenn sie die größte Bedeutung haben.
Sprachmodelle werden mithilfe eines rekurrenten neuronalen Netzes. Diese Architektur des neuronalen Netzes nimmt einen Satz, Wort für Wort, und speist ihn in das Netz ein. Das rekurrente Netz besteht darin, dass die Ausgabe des vorherigen Wortes als Eingabe für das nächste Wort im Satz dient.
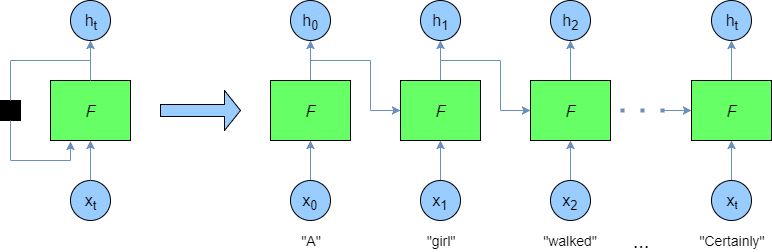
Diese Modelle können nur mit Numbers umgehen. Daher muss der Text in eine Zahl umgewandelt werden. Eine Möglichkeit der Umwandlung von Text in eine Zahl ist die Worteinbettungen.
Eine Worteinbettung verwandelt Wörter in einen 3D-Vektorraum, der die Bedeutung eines Wortes anhand seiner Beziehung zu anderen Wörtern erfassen kann. Ein hervorragendes Beispiel für eine Worteinbettung ist eine Möglichkeit, die Ähnlichkeiten zwischen den Wörtern "Bruder" und "Schwester" im Vergleich zu "Mann" und "Frau" zu verstehen.
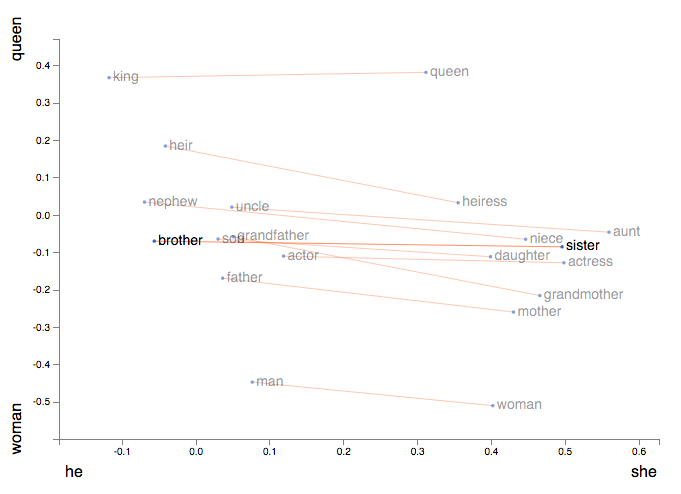
In der obigen Abbildung ist zu erkennen, dass das Wort "Bruder" im gleichen physischen Raum wie das Wort "Mann" liegt. Auch diese Einbettung wurde von einem Modell erlernt, das viele Texte liest und diese Ähnlichkeiten feststellt.
Diese Worteinbettung wird in die nächste Worteinbettung eingespeist, so dass sich das Modell anhand seiner Einbettung an die vorherigen Wörter "erinnern" kann.
Eines der großen Probleme ist, dass sich RNNs im Allgemeinen nicht gut an lange Sätze erinnern können.
Nehmen wir diesen Satz:
"Tony Hung ist ein Software-Ingenieur bei Vonage. Er schreibt gerne über künstliche Intelligenz auf dem Vonage Blog. Er lebt mit seiner Frau, seiner 4-jährigen Tochter und seinem Hund im Bundesstaat New York."
Ein RNN würde jedes Wort ("Tony", "Hung", "is") nehmen und in das Netz als Worteinbettung einspeisen. Im Laufe der Zeit könnte das Modell das Wort "Tony" vergessen, da es das erste Wort im Satz war. Wenn ich dem Modell die folgende Frage stelle: "Wer arbeitet für Vonage", muss es im Satz zurückgehen, das Wort "Vonage" finden und versuchen, das mit der Frage verbundene Substantiv zu finden. Da das Wort "Tony" so weit in der Vergangenheit liegt, ist das RNN möglicherweise nicht in der Lage, es zu finden.
Die Transformer-Architektur hilft bei der Lösung dieses Problems, die in dem Papier vorgeschlagen wurde Aufmerksamkeit ist alles, was Sie brauchen vorgeschlagen wurde und ein Konzept namens Attention verwendet.
Die Aufmerksamkeit ist Teil einer neuronalen Netzwerkschicht, die sich auf bestimmte Teile des Satzes konzentrieren kann. Wie bereits erwähnt, kann ein RNN-Modell jedes Wort des Satzes erfassen, aber wenn die Einbettung zu groß ist, kann sich das Modell möglicherweise nicht an alles erinnern.
Mit Attention enthält jede Einbettung nun auch eine Bewertung, wie wichtig das jeweilige Wort ist. Das RNN muss sich also nicht mehr jede Worteinbettung merken, sondern nur noch die Worteinbettungen mit einer höheren Punktzahl als die anderen Worteinbettungen.
Eine ausführlichere Beschreibung des Transformators und der Aufmerksamkeit finden Sie in Jay Alammars Blogbeitrag zum visuellen Transformator.
Sind Sie noch bei mir? Prima! Kommen wir zu einigen Beispielen, wie GPT-3 verwendet wird.
Mit dem Zugang zur OpenAI-API können Sie Trainingsdaten bereitstellen, die eine Beispiel-Eingabe und die gewünschte Ausgabe enthalten. OpenAI hat das Modell nicht öffentlich zugänglich gemacht, sondern nur als API, die sich in einer geschlossenen Beta-Phase befindet, was bedeutet, dass Sie einen Zugang beantragen müssen, um die API nutzen zu können. Zum Zeitpunkt der Erstellung dieses Artikels wurde ich noch nicht in die Beta aufgenommen.
Die gute Nachricht ist, dass viele Menschen detailliert erklären können, wie die API funktioniert.
Schauen wir uns einige Beispiele anderer Entwickler an, die GTP-3 verwenden.
Eine der vielen Verwendungen von GPT-3 ist die Generierung von HTML aus einer gegebenen Zeichenkette. Die Eingabe in die OpenAI-API würde aus einer Zeichenkette und ihrem HTML-Äquivalent bestehen.
Eingabe: Fettdruck des folgenden Textes: "GPT-3".
Wir würden die Ausgabe von liefern: <b>GPT-3</b>
Die OpenAI-API ermöglicht es einem Entwickler, diese Ein- und Ausgabetexte an GPT-3 zu liefern. Auf den OpenAI-Servern sendet die API diese Ein- und Ausgabetexte an GPT-3, um die gelieferte Eingabe und die gewünschte Ausgabe zu "lernen".
Wenn wir dann eine neue Textreihe an die OpenAI-API übermitteln:
"Zentrieren und fetten Sie das Wort GPT-3".
Die Ausgabe lautet <center><b>GPT-3</b></center>
Wir haben GPT-3 nichts über den <center> Tag, da GPT-3 höchstwahrscheinlich HTML-Zeichenfolgen während seines Trainingsprozesses enthielt.
Hier ist ein Beispiel dafür, wie dies aussehen kann:
Das ist umwerfend.
Mit GPT-3 habe ich einen Layout-Generator gebaut, mit dem man einfach ein beliebiges Layout beschreiben kann, und der dann den JSX-Code für einen generiert.
W H A T pic.twitter.com/w8JkrZO4lk
- Sharif Shameem (@sharifshameem) Juli 13, 2020
Andere Beispiele für Entwickler, die GPT-3 verwenden, sind ein Text-Adventure von aidungeon.io
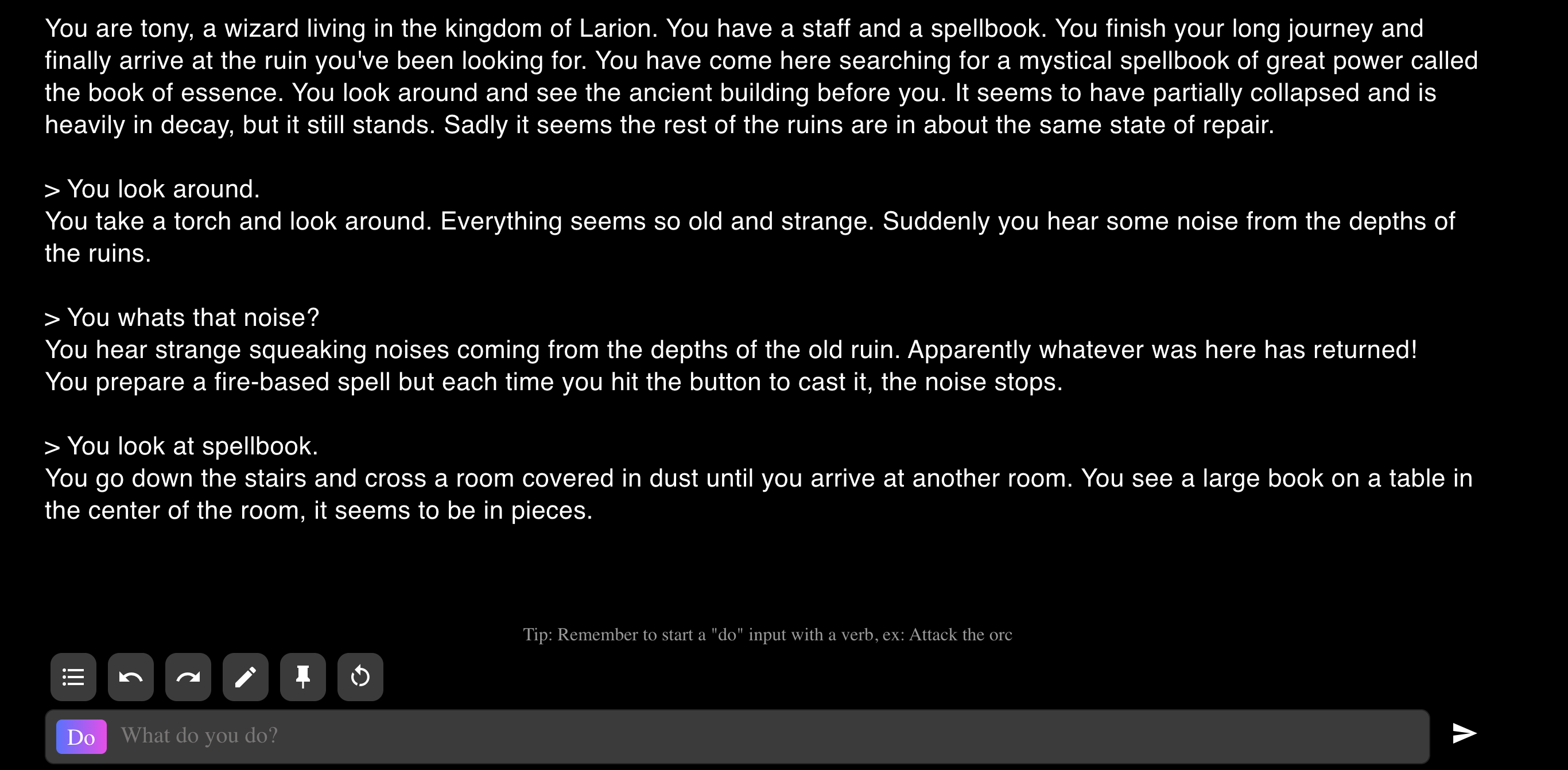 AI Dungeo
AI Dungeo
KI-Dungeon generiert eine Geschichte, in der Sie mit Hilfe von Text navigieren können - auch bekannt als Mehrbenutzer-Dungeon. In diesem Beispiel wird durch die Eingabe der Worte "Look Around" ein neuer Text über die Szenerie generiert. Diese Funktion verwendet nur GPT-3, um den Text nach jeder Eingabe zu generieren.
Dieses Beispiel hat mich überzeugt. Indem Sie eine Reihe von Texteingaben und deren Regex-Äquivalent angeben, können Sie gültige reguläre Ausdrücke in lesbarem Englisch erzeugen.
Ich hatte einmal ein Problem und habe Regex verwendet. Dann hatte ich zwei Probleme
Nie wieder. Mit Hilfe unserer GPT-3-Oberherren habe ich etwas entwickelt, das Englisch in Regex umwandelt. Es hat bei den meisten Beschreibungen, die ich eingegeben habe, gut funktioniert. Anmeldung unter https://t.co/HtTpJ16V4F um mit einem Prototyp zu spielen pic.twitter.com/trJA7VRrsf
- Parthi Loganathan (@parthi_logan) Juli 25, 2020
Weitere Beispiele von Entwicklern, die GPT-3 nutzen, um spannende Dinge zu bauen, finden Sie unter buildgpt3.com.
In diesem Beitrag konnten wir ein grundlegendes Verständnis dafür entwickeln, was GPT-3 ist und wie es aufgebaut ist. Wir sind jedoch nicht zu sehr in die technischen Aspekte dieses und anderer KI-Modelle eingetaucht. Um einen tieferen Einblick in GPT-3 zu bekommen, sehen Sie sich Jay Alammar's Video über die Funktionsweise von GPT-3. Es ist ein guter Ausgangspunkt dafür, wie KI-Modelle trainiert werden können.
Wenn Sie mit den technischen Aspekten der KI, einschließlich Deep Learning, noch nicht vertraut sind, schauen Sie sich bitte folgende Seiten an Fast.aieinen kostenlosen Kurs, der erklärt, was Deep Learning ist und wie man damit anfängt.
Ich hoffe, dieser Beitrag hat Ihnen geholfen zu verstehen, was GPT-3 ist, sowohl von einem technischen als auch von einem nicht-technischen Standpunkt aus. Wenn Sie mehr über GPT-3 und die anderen Projekte von OpenAI erfahren möchten, besuchen Sie bitte OpenAI.com.