Einführung des Audio Connector SDK & Pipecat Serializer für AI Audio Anwendungen
Lesedauer: 4 Minuten
KI-Applikationen in Echtzeit verändern die Art und Weise, wie Entwickler Voice- und Video-Erlebnisse entwickeln. Ob Transkriptionsdienste, Konversationsagenten, Echtzeitübersetzung oder Stimmungsanalyse - moderne Applikationen benötigen zunehmend Zugriff auf Rohdaten in Bewegung, nicht nur am Ende einer Aufnahme oder nach einem Datei-Upload.
PipecatPipecat ist ein Open-Source-Framework, das die Integration der Video- und Voice APIs von Vonage mit Audio-Konnektoren verbessert, indem es eine modulare, herstellerneutrale Plattform für die Orchestrierung von KI-Workflows bietet. Mit Funktionen wie extrem niedriger Latenz, fortschrittlicher Erkennung von Sprachaktivitäten und multimodaler Unterstützung ermöglicht Pipecat Entwicklern die Erstellung von reaktionsschnellen und natürlichen KI-Erlebnissen. Seine Flexibilität ermöglicht die nahtlose Integration mit einer Reihe von KI-Modellen und -Diensten, was es zu einer idealen Wahl für die Entwicklung umfangreicher Audio- und Videoanwendungen in Echtzeit macht.
Um diese nächste Generation intelligenter Applications zu unterstützen, hat Vonage zwei ergänzende Tools speziell für Entwickler eingeführt: das Vonage Audio Connector Python Server SDK und der Vonage Serialisierer für Pipecat. Zusammen erleichtern sie das Audio-Streaming zwischen Vonage Video- und Voice-Sitzungen, WebSocket-Servern und KI-Frameworks wie OpenAI, Deepgram oder AWS Nova Sonic erheblich.
Dieser Blog gibt einen Überblick über diese Tools, erklärt, wie sie zusammenpassen, und bietet Referenzen für den Einsatz Ihres ersten KI-gesteuerten Agenten.
Viele KI-Workflows - Sprache-zu-Text, LLM-gestützte Analyse, Sprachsynthese und multimodale Wahrnehmung - sind auf Echtzeit-Audio angewiesen. Entwickler, die mit den Voice- und Video-APIs von Vonage arbeiten, wünschen sich seit langem eine einfache und zuverlässige Möglichkeit, Audiodaten aus einer aktiven Sitzung zu empfangen, zu verarbeiten und Antworten zurückzusenden.
Der Vonage Audio Connector für die Video API und Voice API WebSocket Integration ermöglicht Entwicklern den Aufbau von WebSocket-Servern, die Vonage-Sitzungen mit AI-Workflows verbinden.
Der Aufbau von WebSocket-Servern mit niedriger Latenz, die Verwaltung binärer Audio-Frames, die Koordinierung von Abtastraten und die Aufrechterhaltung zustandsabhängiger Verbindungen können jedoch komplex und fehleranfällig sein. Diese Komplexität verlangsamt oft Experimente, Proof-of-Concept-Entwicklungen und Produktionsbereitstellungen.
Das Vonage Audio Connector SDK beseitigt diese Reibung.
Die Toolchain unterstützt eine breite Palette von Echtzeit-KI-Erfahrungen, darunter:
Sprache-zu-Text-Transkription
LLM-basierte Sitzungsassistenten
Analyse von Gefühlen oder Absichten bei Live-Anrufen
Interaktive Voice-Bots
Sprachübersetzung in Echtzeit
Automatisierte Notizen oder Zusammenfassungen
Audiomoderation und Erkennung von Verstößen
Das folgende Diagramm zeigt die Architektur einer Video- oder Voice-Sitzung, die mit dem Audio Connector SDK über einen WebSocket integriert ist. Das SDK ist ein Python-Paket (verfügbar auf PyPI), das die Komplexität der Verwaltung von WebSocket-Audioströmen aus Vonage-Sitzungen abstrahiert.
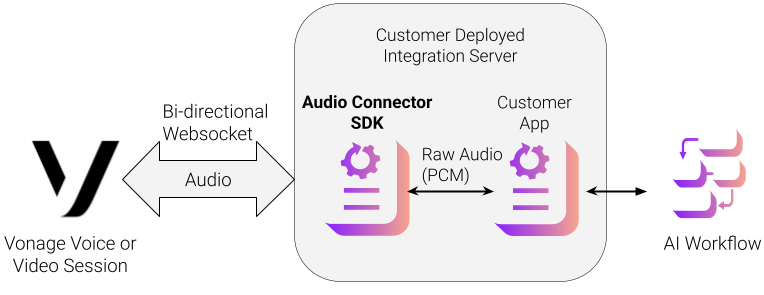
Ereignisgesteuerter WebSocket-Server zum Empfangen und Senden von PCM-Audio
Unterstützung für 8 kHz, 16 kHz und 24kHz Samples mit automatischer Rahmenverarbeitung
Saubere asynchrone Rückrufe für Connect-, Disconnect-, Message- und Error-Ereignisse
Integrierte Pufferung und Zeitsteuerung für reibungslose Wiedergabe
Mehrere gleichzeitige Verbindungen für Multi-Agenten- oder Multi-Teilnehmer-Workflows
TLS-Unterstützung für sichere Produktionsimplementierungen
So können sich die Entwickler ganz auf das konzentrieren, was sie bauen wollen - Transkriptionspipelines, Analysetools, Sprachassistenten -, ohne dass sie eine WebSocket-Infrastruktur schreiben müssen.
Das SDK kann mit Hilfe eines Python-Paketmanagers aus dem Python Package Index installiert werden.
pip install vonage-audio-connector-server
Die SDK-Entwicklerhandbuch bietet eine grundlegende Referenz zum Konfigurieren/Starten des WebSocket-Servers, zum Einrichten asynchroner Handler für die Sitzungs- und Audioverwaltung und zum Einspeisen von Audio in die Video-Sitzung über den WebSocket.
Informationen zum Öffnen einer WebSocket-Verbindung von einer Video-Sitzung zu einem Server unter Verwendung des SDK finden Sie auf der Audio Connector-Entwicklerseite. Informationen zum Öffnen einer WebSocket-Verbindung von einer Voice-Konversation zu einem Server unter Verwendung des SDK finden Sie auf der Voice WebSockets-Entwicklerseite.
Sie können den Beispielcode für die Verwendung des Audio Connector SDK aus dem GitHub-Repository
Pipecat ist ein Open-Source-Framework für die Orchestrierung komplexer KI-Workflows für Audio, Video, Bilder und Text. Für audio-orientierte Applikationen ist der neue Vonage Serializer für Pipecat als Brücke zwischen den Vonage Voice- und Video-Sitzungen und einer Pipecat-Verarbeitungspipeline.
Konvertiert eingehende Vonage-Audio-Frames in das interne Frame-Format von Pipecat
Angleichung von Abtastraten und Audiocodierungen
Unterstützt DTMF und andere Metadaten
Konvertiert ausgehende Pipecat-Audio-Frames zurück in Vonage WebSocket-Frames
Das bedeutet, dass Entwickler die wachsende Liste der KI-Knoten von Pipecat - OpenAI Realtime, Deepgram, Whisper, ElevenLabs usw. - nutzen können, ohne einen Code für die Medienübersetzung schreiben zu müssen.
Der Serializer stellt eine direkte Verbindung zwischen dem Audio eines Live-Teilnehmers und einem vollständig programmierbaren AI-Workflow her.
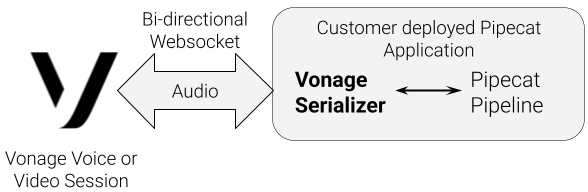
Die Serializer-Anleitung bietet eine grundlegende Referenz für das Einrichten des Vonage Serializers mit Pipecat.
Verwendung des Vonage Audio Connector SDK oder Pipecat Serializer bietet Entwicklern eine saubere, moderne und Python-freundliche Möglichkeit, Echtzeit-Audio-Agenten zu erstellen, ohne WebSocket-Server oder Medien-Pipelines neu erfinden zu müssen.
Ganz gleich, ob Sie einen Voice-Bot erstellen, Sprache-zu-Text mit einem LLM integrieren, synthetische Antworten in Echtzeit generieren oder das Anrufverhalten analysieren möchten, diese Tools bieten Ihnen die erforderlichen Grundlagen.
Wenn Sie bereit sind, zu beginnen, erkunden Sie:
Das PyPI-Paket für das Audio Connector SDK
Beispiel-Applikationen für das SDK
Vonage Beispiele im Pipecat-Repositorium
Mit diesen Tools können Sie Ihren ersten KI-Agenten in wenigen Minuten einrichten - und mit Zuversicht auf vollständig intelligente, medienkompatible Applikationen auf der Vonage Plattform hinarbeiten.
Haben Sie eine Frage oder möchten Sie uns mitteilen, was Sie gerade bauen?
Beteiligen Sie sich am Gespräch auf dem Vonage Community Slack
Abonnieren Sie den Entwickler-Newsletter
Folgen Sie uns auf X (früher Twitter) für Updates
Sehen Sie sich die Tutorials auf unserem YouTube-Kanal
Verbinden Sie sich mit uns auf der Vonage Entwickler-Seite auf LinkedIn
Bleiben Sie auf dem Laufenden und halten Sie sich über die neuesten Nachrichten, Tipps und Veranstaltungen für Entwickler auf dem Laufenden.