
Teilen Sie:
Max ist ein ehemaliges Mitglied des Vonage-Teams. Er war Python Developer Advocate und Softwareentwickler und interessierte sich für Kommunikations-APIs, maschinelles Lernen, Developer Experience und Tanz! Er hat Physik studiert, arbeitet aber mittlerweile an Open-Source-Projekten und entwickelt Lösungen, die das Leben von Entwicklern erleichtern.
Verbessern Sie Ihr Softwareprojekt - Teil drei: Erweiterungen der nächsten Stufe
Lesedauer: 13 Minuten
Haben Sie schon einmal eine Codebasis übernommen und festgestellt, dass Sie mit der Art, wie der Code geschrieben oder organisiert ist, nicht zufrieden sind? Das kommt häufig vor, kann aber eine Menge Kopfschmerzen verursachen. Technische Schulden können zu einem Schneeballsystem werden, das es exponentiell schwieriger macht, den Code zu verstehen und neue Funktionen hinzuzufügen.
In dieser dreiteiligen Serie gehe ich auf einige der wichtigsten Dinge ein, die Sie tun sollten, um mit Ihrem glänzenden (alten) Projekt zufriedener zu werden. Anhand einiger konkreter Beispiele werde ich erläutern, wie ich das Open-Source Vonage Python SDKeine Bibliothek, die HTTP-Aufrufe zu Vonage-APIs macht, aber die Prinzipien gelten für jede Art von Softwareprojekt.
Die Beispiele in diesem Beitrag werden in Python geschrieben, aber diese Prinzipien gelten für Projekte in jeder Sprache. Außerdem gibt es eine praktische Checkliste, die Sie befolgen können wenn Sie speziell versuchen, ein Python-Projekt zu reparieren.
Dritter Teil: Erweiterungen der nächsten Stufe (dieser Artikel)
Wenn Sie gefolgt sind Teil eins und Teil Zwei dieser Reihe verfolgt haben, kennen Sie Ihr Projekt gut und haben vielleicht schon einige Überarbeitungen vorgenommen, Funktionen hinzugefügt und neue Versionen veröffentlicht.
Im dritten Teil werden wir darüber sprechen:
Ihr Projekt verbessern
Werkzeuge, die Sie verwenden können
Automatisierung
Bewährte Verfahren für die Übergabe eines Projekts an eine andere Person
Wenn man über Verbesserungen nachdenkt, die an einer Codebasis vorgenommen werden können, fallen sie in zwei Gruppen:
Verbesserungen, die dem Nutzer direkt zugute kommen, und
Verbesserungen, die dem Betreuer zugute kommen.
Lassen Sie uns zunächst einige Verbesserungen für die Benutzer erörtern.
Wenn ein Benutzer auf einen Fehler stößt, kann es sehr unterschiedlich sein, wie nützlich dieser Fehler ist, um ihm zu helfen, herauszufinden, was falsch ist. Betrachten wir zwei unterschiedliche Beispiele.
Beispiel A zeigt eine Möglichkeit, eine Funktion zu schreiben, die prüft, ob ein Eingabeparameter für eine Methode gültig ist. Die betreffende Methode ermöglicht es einem Benutzer, Nachrichten über Kanäle wie SMS, MMS, WhatsApp, Messenger und Viber mit der Vonage Messages API. Diese Prüfung stellt sicher, dass der Benutzer einen gültigen Kanal angegeben hat.
def _check_valid_message_channel(self, params):
if params['channel'] not in Messages.valid_message_channels:
raise ExceptionWenn der Benutzer in diesem Fall keinen gültigen Nachrichtenkanal angibt, wird er lediglich feststellen, dass eine Ausnahme ausgelöst wurde. Er erhält hier keine spezifischen Informationen und muss seinen Aufrufstapel durchforsten, um die Fehlerursache zu ermitteln.

Anhang B zeigt eine andere Möglichkeit, diesen Code zu schreiben.
from .errors import MessagesError
def _check_valid_message_channel(self, params):
if params['channel'] not in Messages.valid_message_channels:
raise MessagesError(f"""
'{params['channel']}' is an invalid message channel.
Must be one of the following types: {self.valid_message_channels}'
""")In diesem Fall habe ich einen benutzerdefinierten Fehler im Zusammenhang mit der Vonage Messages API erstellt. Ich gebe eine Fehlermeldung an, die das genaue Problem mit dem Code des Benutzers beschreibt, und was er tun kann, um es zu beheben. Das ist für den Benutzer viel klarer und kann ihm viel Zeit bei der Fehlersuche sparen!

Wir sehen oben, dass der Benutzer versucht hat, eine Brieftauben-Nachricht über die Messages API zu senden, was ein nicht unterstützter Kanal ist. Dieses Beispiel zeigt, wie sehr Sie Ihren Benutzern helfen können, wenn Sie benutzerdefinierte Ausnahmen erstellen, die bei der Fehlersuche helfen.
Wenn Ihre Benutzer Daten an Funktionen in Ihrem Code übergeben müssen, sollten Sie überlegen, welche Prüfungen Sie für diese Eingabedaten durchführen. Wenn Sie einen stark typisierten, klassenbasierten Ansatz wie objektorientiertes Java verwenden, wird Ihr Code versuchen, die Eingabedaten in eine geeignete Struktur zu bringen. Wenn Sie einen weniger strengen Ansatz verwenden, sollten Sie die Benutzereingabe validieren, um so schnell wie möglich einen Fehler zu melden, wenn etwas nicht in Ordnung ist.
Schauen wir uns ein paar echte Beispiele an. Dies ist ein Code aus dem SDK, der eine SMS sendet:
def send_message(self, params):
...
return self._client.post(
self._client.host(),
"/sms/json",
params, # This is the user's input!
supports_signature_auth=True,
**Sms.defaults,
)Wenn Sie diese Methode aufrufen, passieren folgende Dinge:
paramswerden vom Benutzer an diesms.send_messageFunktion durch den BenutzerDiese Werte werden sofort an eine andere Funktion übergeben, die
postMethode derclientKlasseDie Methode
postMethode stellt eine Post-Anfrage und gibt die Antwort an den Benutzer zurück.
Bei diesem Vorgang wird die Benutzereingabe sofort dem params Objekt zugewiesen, ohne dass eine Validierung stattfindet. Für einfache Fälle ist dies in Ordnung, aber wenn die API, mit der wir kommunizieren, viele Kombinationen von Optionen zulässt, sollten wir eine Validierung der Benutzereingabe in Betracht ziehen.
Gute Frage. Warum sollten wir uns die Mühe machen, wenn wir sowieso nur einen Fehler auslösen werden? Nun, dies ist ein perfektes Beispiel für den "Fail-Fast"-Ansatz: Das Abfangen von Fehlern an der Wurzel des Problems macht die Fehlersuche viel einfacher und bedeutet, dass weniger Ressourcen für Anfragen verwendet werden, die abgelehnt werden.
Hier ist ein weiteres Beispiel, diesmal von der Vonage Messages API:
def send_message(self, params: dict):
self.validate_send_message_input(params) # This calls the function below
...
return self._client.post(
self._client.api_host(),
"/v1/messages",
params, # This is still the user's input, but if we get here, we know it's valid!
auth_type=self._auth_type,
)
def validate_send_message_input(self, params):
# Each of these lines calls a different check on the user's input
# An error is thrown if any of the checks fail
self._check_input_is_dict(params)
self._check_valid_message_channel(params)
self._check_valid_message_type(params)
self._check_valid_recipient(params)
self._check_valid_sender(params)
self._channel_specific_checks(params)
self._check_valid_client_ref(params)Wie wir sehen, wird die Eingabe des Benutzers diesmal sorgfältig geprüft, damit wir keine fehlerhafte Anfrage senden.
Manuelle Überprüfungen sind zwar effektiv, aber es lohnt sich auch, einen klassen- oder modellbasierten Ansatz in Betracht zu ziehen, wenn Sie viele Benutzereingaben validieren müssen. In einigen Sprachen ist diese Funktion über stark typisierte Klassen implementiert, wobei der Konstruktor einer Klasse bestimmte Eingaben erwartet, um eine Instanz dieser Klasse zu erzeugen. In diesem Fall kann man sicherstellen, dass der Benutzer gültige Klassen erstellt und diese an die anderen Funktionen weitergibt, um die richtigen Daten zu erhalten. In Python gibt es kein sofort einsatzbereites Typisierungssystem, das auf diese Weise funktioniert, aber es gibt Bibliotheken wie Pydantic die Modelle erstellen können, um dies für Sie zu tun.
Ich habe den obigen Code mit einem modellbasierten Ansatz mit Pydantic umgeschrieben, um Modelle für die Eingabevalidierung zu verwenden:
# I created models (that look like classes) that inherit from Pydantic's BaseModel class.
# I'm able to specify specific constraints, including the type and length of parameters, and specify defaults.
class Message(BaseModel):
to: constr(min_length=7, max_length=15)
sender: constr(min_length=1)
client_ref: Optional[str]
class SmsMessage(Message): # Inherits the properties of the "Message" model
channel = Field(default='sms', const=True)
message_type = Field(default='text', const=True)
text: constr(max_length=1000)
... # More classes for each type of message that the Messages API can send
class Messages: # Class that contains the code to call the Messages API
... # Skipping showing the constructor etc. here
def send_message_from_model(self, message: Message):
params = message.dict()
...
return self._client.post(
self._client.api_host(),
"/v1/messages",
params,
auth_type=self._auth_type,
)Diese Version sieht vielleicht komplizierter aus als die obige, aber sie erspart uns das manuelle Schreiben aller Prüfungen. Wenn nun ein Benutzer eine Nachricht senden möchte und einen Teil der Eingabe falsch macht, erhält er eine sinnvolle Fehlermeldung, die angibt, was er falsch gemacht haben könnte.

Jetzt ist die Validierung eng an die Instanziierung von Klassen gekoppelt. In der vorherigen Implementierung musste die Validierung manuell geschrieben werden und war nicht zwingend erforderlich. Mit dem modellbasierten Ansatz von Pydantic können wir garantieren, dass es keine Möglichkeit mehr gibt, ungültige Eingaben zu übergeben.
Zusammenfassend lässt sich sagen, dass Sie bei der Bearbeitung von Benutzereingaben eine Validierung in Betracht ziehen sollten. Wie Sie diese Validierung durchführen, hängt von Ihrer Sprache und dem gewählten Ansatz ab, aber eine Form der Validierung kann Ihren Benutzern viel Zeit ersparen.
Die letzte potenzielle Verbesserung für den Benutzer, die ich aufzeigen möchte, hat mit asynchronem Code zu tun. Sofern Ihr Projekt nicht mit io-gebundenen Operationen zu tun hat, müssen Sie dies vielleicht gar nicht berücksichtigen - in diesem Fall können Sie einfach zum nächsten Abschnitt übergehen.
Asynchroner Code ist Code, bei dem Operationen die Kontrolle über einen Thread abgeben können, damit andere Dinge geschehen können. Vergleichen Sie das mit synchronem Code, der darauf wartet, dass jede Operation abgeschlossen ist, bevor die nächste gestartet wird. Einige Sprachen (z. B. Node.js) sind standardmäßig asynchron, aber andere Sprachen verfügen über asynchrone Funktionen, die bei Bedarf genutzt werden können. Wenn Sie ein JavaScript-Entwickler sind, können Sie diesen Abschnitt wahrscheinlich überspringen.
Wenn Ihr Code eine Anfrage stellt und lange auf eine Antwort warten muss, kann es sich lohnen, Ihren Code asynchron zu schreiben und andere Dinge geschehen zu lassen, bis Sie eine Antwort erhalten. Im Fall des Python-SDK von Vonage stellen wir HTTP-Anfragen an einen Remote-Server. Da dies synchron geschieht, ist es eine Überlegung wert, ob eine asynchrone Version eines Teils des SDKs für meine Benutzer von Vorteil wäre. Wir können vermuten, dass eine asynchrone Methode es möglich machen würde, mehr Anfragen auf einmal mit dem SDK zu senden... aber warum raten? Lassen Sie uns ein Experiment machen.
Um herauszufinden, ob einige asynchrone Methoden die Zeit für die Ausführung von Anfragen verringern würden, habe ich zwei Code-Teile geschrieben. Einer verwendete eine Funktion aus dem Vonage Python SDK, um 100 HTTP-Anfragen an die Number Insight API von Vonage und der andere verwendete eine asynchrone Version der von mir erstellten Funktion. Ich habe für beide Versionen des Codes ein Profil erstellt (mit Hilfe der Profiling-Methode, die ich im ersten Teil dieser Serie beschrieben habe, hier) und wir können sehen, dass die meiste Zeit im Programm für HTTP-Anfragen aufgewendet wird.
Das erste Bild unten ist ein Eiszapfen-Diagramm, das den oberen Teil des Aufrufstapels für unser SDK zeigt, während es 100 Anfragen an eine Vonage-API stellt.
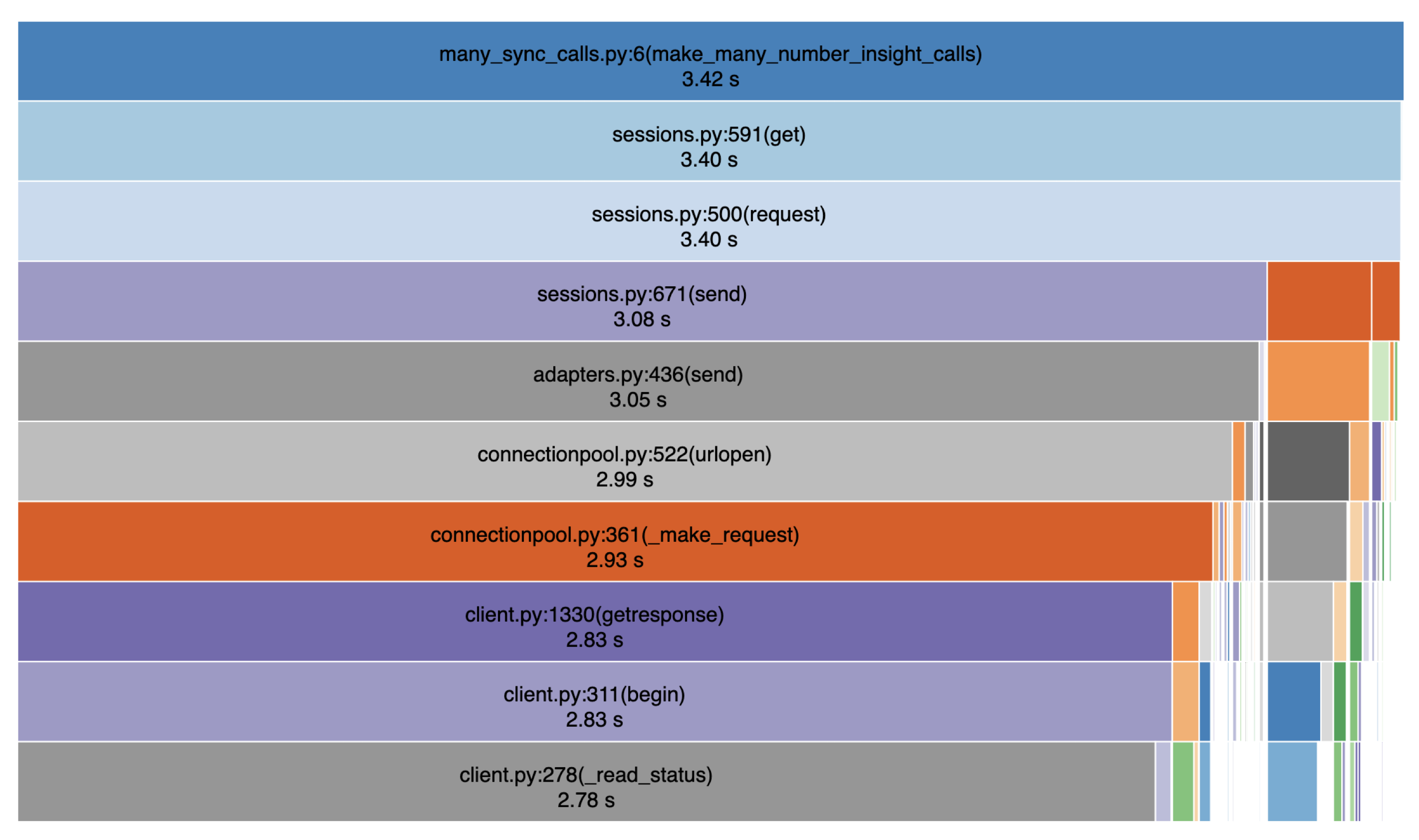
Das nächste Bild zeigt das unterste Ende des Aufrufstapels. Wie Sie hier sehen können, wird die meiste Zeit, die das gesamte Programm zur Ausführung benötigt (2,78/3,42 Sekunden, also 81 %!), damit verbracht, auf SSL-Verbindungen zwischen unserem Code und dem Remote-Server zu warten. Und das ist nur ein Teil des Prozesses, auf den wir warten müssen, wenn wir Sync-Aufrufe tätigen.

Dies deutet darauf hin, dass die Laufzeit viel kürzer sein könnte, wenn der Code die Kontrolle über den Thread aufgeben könnte, bis die Verbindungen hergestellt sind! Nachfolgend finden Sie die Daten für eine asynchrone Version des Codes, die dieselben 100 Anfragen an dieselbe API durchführt.

Aus dem obigen Diagramm ist ersichtlich, dass die gesamte Aufgabe in 0,33s abgeschlossen wurde, also etwa 10 Mal schneller als die synchrone Version! In diesem Fall macht es Sinn, zu untersuchen, ob ich meinen Code asynchron machen sollte.
Der letzte Absatz scheint ziemlich unverbindlich, wenn man bedenkt, dass ich den Code gerade 10x schneller gemacht habe. Warum sollte ich nicht sofort mit der Asynchronisierung meines Codes beginnen wollen? Nun, es kann die Dinge sehr viel komplizierter machen.
Während asynchroner Code in vielen Fällen gut funktioniert, hat er auch erhebliche Nachteile. Um meinen Code asynchron zu machen, müsste ich einen großen Teil davon neu schreiben. In Python verhalten sich asynchrone Coroutines ganz anders als normale Methoden; sie müssen ganz anders aufgerufen und behandelt werden.
Schlimmer noch ist die Frage des Supports. Wenn ich die gesamte Bibliothek vollständig umschreiben würde, um sie asynchron zu machen, und eine neue Hauptversion des Projekts veröffentlichen würde (wie in Teil 2 besprochen), würde ich meine Benutzer dazu zwingen, ihren gesamten Code, der mein SDK verwendet, neu zu schreiben! Wenn ich meinen Benutzern diese Tortur nicht zumuten wollte, müsste ich synchrone und asynchrone Versionen desselben Codes pflegen, was die Größe der Codebasis effektiv verdoppeln würde. Das bedeutet, dass ich doppelt so viel Code testen muss, und wenn ich neue Funktionen hinzufügen wollte, müsste ich sie doppelt einbauen.
Es gibt Möglichkeiten, die Belastung zu verringern, aber das Hinzufügen von asynchroner Unterstützung wäre immer noch eine erhebliche Zeitinvestition. Insgesamt ist async sehr leistungsfähig, aber überlegen Sie sorgfältig, was die Anwendungsfälle für Ihre Codebasis sind. Wenn Sie der Meinung sind, dass es einen großen Nutzen bringt, sollten Sie async in Erwägung ziehen, aber überlegen Sie es sich sehr genau, bevor Sie sich dazu verpflichten, es umzusetzen. Und wenn Sie ein JavaScript-Programmierer sind, der diesen Abschnitt liest, obwohl Ihr Code sowieso so funktioniert, hoffe ich, dass dies aufschlussreich oder zumindest unterhaltsam war. 🤷
Wenn Sie in das langfristige Wohlergehen Ihres Projekts investieren wollen, werden Sie wahrscheinlich Werkzeuge einrichten wollen, die Sie beim Schreiben Ihres Codes unterstützen oder Ihnen Einblicke in Aspekte des Codes geben. Ich erwähnte einige Werkzeuge in Teil eins dieser Serie aber lassen Sie uns jetzt etwas praktischer über die Anwendung automatisierter Werkzeuge auf Ihren Code sprechen.
Vorausgesetzt, Ihr Code verwendet eine Versionskontrolle, ist es möglich, Werkzeuge einzurichten, die ausgeführt werden, wenn der Code gepusht wird, wenn PRs gemacht werden usw. Es gibt viele Tools, die dies ermöglichen. In meinem Fall verwendet das Vonage Python SDK GitHub-Aktionendas für Open-Source-Projekte, die auf GitHub gehostet werden, und sogar für private GitHub-Repos unterhalb einer bestimmten Nutzungsquote kostenlos ist.
In meinem Repo, habe ich eine GitHub-Aktion eingerichtet eingerichtet, die Tests ausführt, wenn ein Push oder PR gemacht wird und die Codeabdeckung berechnet. Der Vorteil der Automatisierung ist, dass ich auf mehreren Plattformen und Python-Versionen testen kann, ohne für jede Plattform eine VM und für jede Python-Version eine neue virtuelle Umgebung einrichten zu müssen. Ich empfehle Ihnen, Ihre Tests so einzurichten, dass sie auf diese Weise ausgeführt werden, da Sie Fehler abfangen können bevor bevor sie in Ihre Produktionsumgebung gelangen.

Unter Teil eins dieser Serie sind wir kurz auf die Vorteile eingegangen, die Mutationstests mit sich bringen können. Es kann leicht passieren, dass man in die Codeabdeckungsfalle tappt und die Abdeckung um jeden Preis erhöht. Goodharts Gesetz besagt: "Wenn eine Maßnahme zu einem Ziel wird, hört sie auf, eine gute Maßnahme zu sein". Entwickler, die sich zu sehr mit Codeabdeckungsmetriken beschäftigen, neigen dazu, die Testqualität der Quantität der Abdeckung zu opfern. Der Mutationswert ist eine Möglichkeit, dies zu verhindern.
Der Mutationswert bezieht sich auf die Fähigkeit Ihrer Tests, auf Änderungen zu reagieren. Wie wir im ersten Teil besprochen haben, funktionieren Mutationstests, indem Sie Ihren Code auf subtile Weise ändern und dann Ihre Unit-Tests auf diese neuen, "mutierten" Versionen Ihres Codes anwenden.
Die Durchführung von Mutationstests kann bei einer größeren Codebasis einige Zeit in Anspruch nehmen. Da es sich hierbei jedoch um eine automatisierte Testmethode handelt, ist es glücklicherweise möglich, Mutationstests in eine Build/Release-Pipeline einzubauen. Ich beschloss, dies für das Python-SDK von Vonage zu tun, indem ich eine Python-Mutationsbibliothek namens mutmut.
Ich habe eine GitHub-Aktion "Mutation Test" eingerichtet, die einen Mutationstest auf der Codebasis durchführt, wie unten gezeigt:
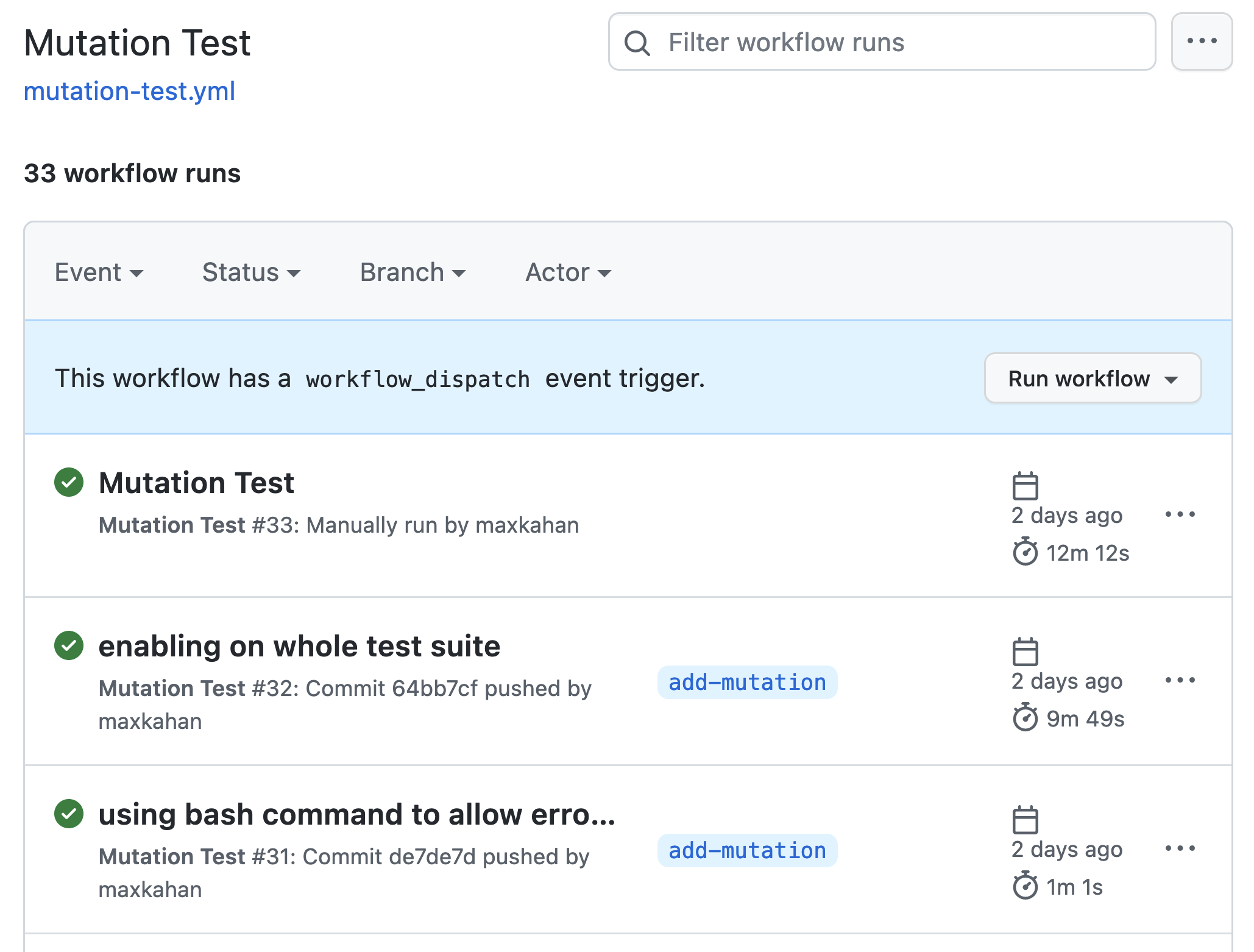
Dieser Workflow hat einen manuellen Auslöser. Der Grund dafür ist, dass ein automatischer Lauf bei Push oder PR länger dauern würde, als ich es mir wünsche. Wenn der Workflow manuell ausgelöst wird, kann ich ihn immer dann ausführen, wenn ich einen Einblick in den Zustand meiner Codebasis gewinnen möchte.

Der Arbeitsablauf des Mutationstests erzeugt eine HTML-Ausgabe, die innerhalb des jeweiligen Testlaufs zum Herunterladen bereitgestellt wird. Diese enthält eine Indexdatei mit einer Übersicht und dann eine Liste der Mutationen, die sich der Erkennung für jedes Modul entzogen haben.
Hier sehen wir, dass wir 383/522 mutierte Versionen des Codes gefunden haben, das sind etwa 74 %. Das ist ein guter Wert, aber wir können einige Diskrepanzen zwischen den Modulen erkennen und sollten die Ursache dafür untersuchen. Es ist nicht immer produktiv, die höchste Punktzahl anzustreben (denken Sie an Goodharts Gesetz!), aber wir können diese Metriken nutzen, um besser zu verstehen, was unsere Tests tun. Ein Mutationswert, der sich ständig verbessert (wenn auch sehr langsam), ist wichtiger als ein hoher Wert.
Wenn Ihr Projekt Abhängigkeiten verwendet, sollten Sie sicher sein, dass Sie Versionen verwenden, die die Sicherheit Ihrer Benutzer nicht gefährden. Viele automatisierte Tools können dies für Sie überprüfen, z.B. Mend für GitHub.comdas Ihren Code regelmäßig nach Schwachstellen durchsucht und Probleme und PRs veröffentlicht, um Schwachstellen zu beheben.
Die Verwendung eines Tools, das Datenbanken mit Schwachstellen und Sicherheitshinweisen verfolgt, ist wichtig, da ständig neue Bedrohungen entdeckt werden.
In dieser Serie ging es hauptsächlich um die Situation, dass Sie mit der Arbeit an einem Altprojekt begonnen haben, aber wahrscheinlich nicht für immer für dieses Projekt verantwortlich sein werden. Irgendwann werden Sie den Code wahrscheinlich an jemand anderen übergeben, und es ist eine gute Praxis, Ihre letzten Wochen mit einem Projekt zu nutzen, um sicherzustellen, dass die Übergabe so reibungslos wie möglich verläuft. Sie haben vielleicht schon von der Regel gehört, die Bob Martin von den Scouts übernommen hat: Hinterlassen Sie den Code in einem besseren Zustand als Sie ihn vorgefunden haben.
2 Wochen vor der Übergabe ist es an der Zeit, keine neuen Aufträge mehr anzunehmen. Ihre Aufgabe zu diesem Zeitpunkt sollte es sein, eine nahtlose Übergabe zu schaffen. Schließen Sie alle Funktionen ab oder stellen Sie sie ein und führen Sie alle offenen PRs zusammen oder schließen Sie sie. Idealerweise sollten Sie so schnell wie möglich mit dem wichtigen Prozess des Niederschreibens beginnen.
Dokumentieren Sie den Stand des Codes. Dazu gehört, dass Sie sicherstellen, dass die READMEs und Dokumentationen auf dem neuesten Stand sind, falls der Code eine Zeit lang nicht angefasst wird, aber auch: Schreiben Sie ein Übergabedokument! Sie wollen nicht, dass Ihr Nachfolger sich durch viele offene Zweige von nicht freigegebenem Code wühlen muss, um herauszufinden, was Sie geplant haben. Ihr Übergabedokument sollte Folgendes enthalten:
Ein Überblick über die Codebasis
Wie man mit der Entwicklung des Projekts beginnt
Überblick über die Tests
Die Arbeit, die Sie begonnen, aber nicht beendet haben
Die Arbeit, die Sie geplant haben, und warum
Alles andere, was undokumentiert oder nicht offensichtlich ist
Schließlich könnte sich Ihr Nachfolger an Sie wenden, um den Kodex zu besprechen. Wenn Sie Zeit haben, sollten Sie sich mit ihnen auseinandersetzen. Es ist schön, nett zu sein!
Wenn Sie dies lesen, herzlichen Glückwunsch! Sie sind in einer großartigen Position, um ein Projekt, das Sie besitzen, so fantastisch zu machen, wie es nur möglich ist.
Wenn Sie Fragen haben oder uns Ihre Gedanken mitteilen möchten, können Sie uns auf unserem Vonage Community Slack oder senden Sie uns eine Nachricht auf Twitter.
Vielen Dank, dass Sie mich auf dieser Reise begleitet haben, und viel Erfolg bei all Ihren zukünftigen Projekten.
Teilen Sie:
Max ist ein ehemaliges Mitglied des Vonage-Teams. Er war Python Developer Advocate und Softwareentwickler und interessierte sich für Kommunikations-APIs, maschinelles Lernen, Developer Experience und Tanz! Er hat Physik studiert, arbeitet aber mittlerweile an Open-Source-Projekten und entwickelt Lösungen, die das Leben von Entwicklern erleichtern.